arXiv'26 | 为什么你的多智能体系统越加 agent 越慢?DeLM 用去中心化解了这个矛盾
为什么你的多智能体系统越加 agent 越慢?DeLM 用去中心化解了这个矛盾
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

原文:Decentralized Multi-Agent Systems with Shared Context(Yuzhen Mao, Azalia Mirhoseini, Stanford University)
1. 前言:你有没有发现,多 agent 系统加着加着就变慢了?
你有没有想过,当你给一个多智能体系统(Multi-Agent System, MAS)不断加 agent、想让它”并行干活更快”时,背后实际发生了什么?
直觉上,多个 agent 同时探索不同子任务,应该是越多越快才对。但凡是真正搭过 MAS 的人都知道,现实往往相反:子任务越多,系统反而越慢、越绕、越贵。
这个问题比表面看起来复杂得多。今天想和大家聊聊 Stanford 这篇 DeLM(Decentralized Language Models),它把这个”越加越慢”的怪现象直接归因到一个东西上——中心化调度(centralized orchestration),然后用一套去中心化的设计把它干掉了。
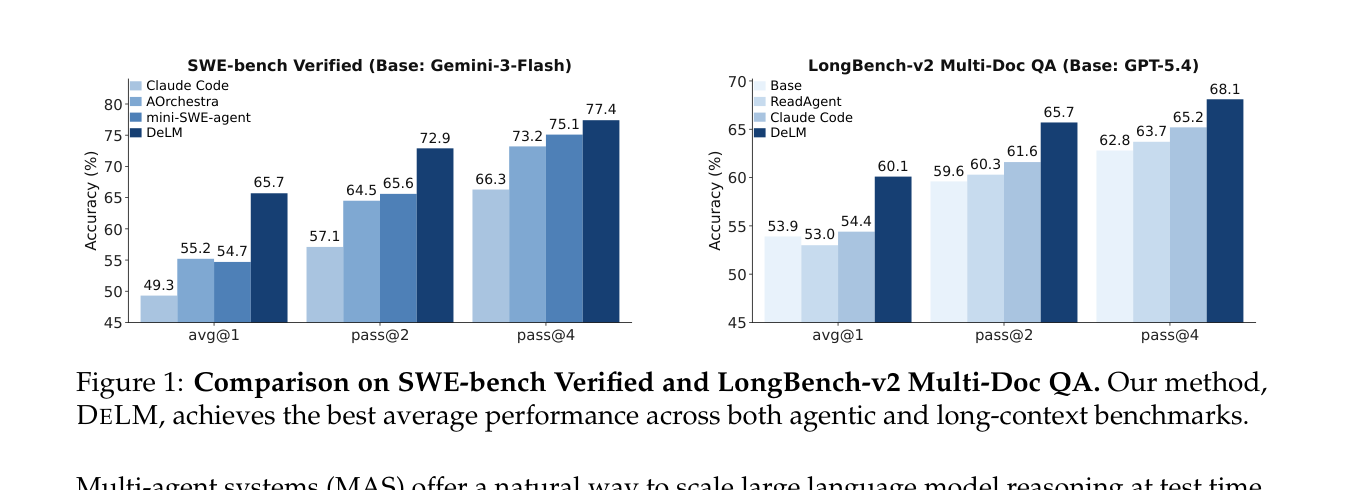
先说结论:DeLM 在 SWE-bench Verified 和 LongBench-v2 两个差异极大的任务上都拿到了最好的平均表现,最高比最强 baseline 高 10.5 个百分点,同时把每个任务的成本砍掉了大约一半。
2. 核心矛盾:中心 agent 就是那个瓶颈
先交代下背景。现在主流的 MAS 长啥样?
绝大多数都是中心化的:有一个 primary agent(主 agent / orchestrator)负责拆任务、把子任务派给 worker、收集结果、再决定下一步。所有的协调决策、所有的中间进展,都要经过这个主 agent 来路由(route)。
问题就出在这。当子任务规模增长时,这个主 agent 就成了那个绕不过去的瓶颈:
- 每个 worker 干完活,都要把结果交还给主 agent,主 agent 再触发下一轮检索或委派;
- worker 之间想共享一个发现?对不起,不能直接说,得先汇报给主 agent,主 agent 再转发;
- 子任务越多,这种”来回汇报—再分发”的 overhead 就越重,协调越来越串行化、越来越被一个过载的主 agent 卡死。
说人话就是:你以为是并行,实际上所有信息流都要穿过中心那一个点,本质上还是串行。这跟”并行执行本身并不等于并行的进展共享”是两码事。
这也是整个多智能体方向需要解决的核心矛盾:你想要 parallel scaling(多个 agent 并发探索),但中心化的通信机制把并行的红利又吃回去了。
3. DeLM 怎么做的:把”中心调度”换成”共享内存 + 任务队列”
DeLM 的 key idea 一句话能说清:
不要让 agent 反复把信息路由给一个中心控制器,而是让它们通过一个共享的、经过校验的上下文(shared verified context)异步地协调。
如下图,DeLM 围绕三个组件转:任务队列(Task Queue)、并行 agents、共享上下文(Shared Context)。Agent 从队列里认领(claim)子任务,读取已经累积的进展,做本地推理,然后把结果以紧凑、已校验的更新写回共享上下文。整个过程没有中心 agent 来 merge、过滤、再分发。
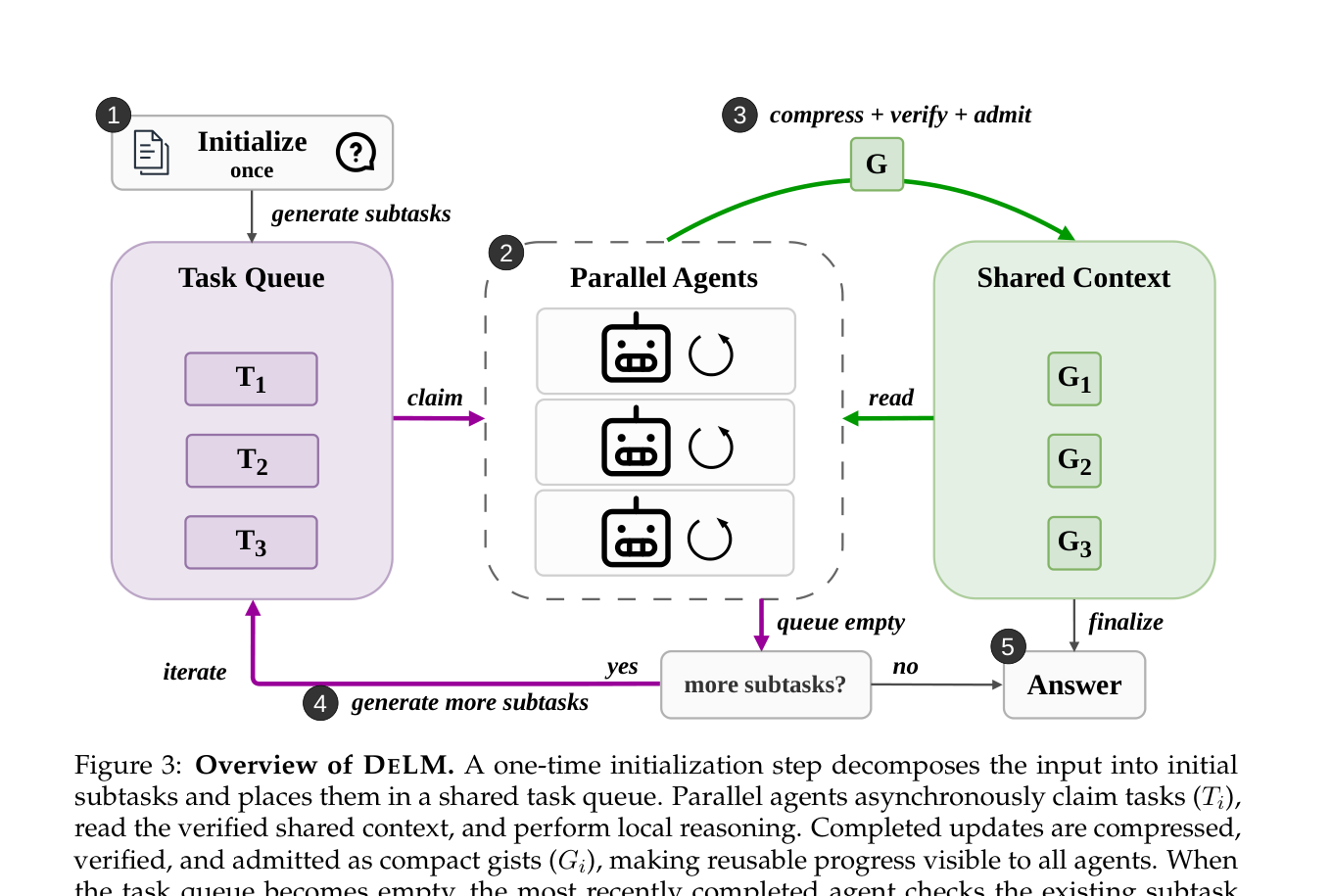
3.1 两个全局结构:共享上下文 C 和任务队列 T
DeLM 维护两个全局结构:
- 共享上下文 C:存的是压缩后的问题状态、可复用的中间结论、被证伪的假设、失败、约束等等——注意,存的是摘要(gist)而不是原始 raw output。
- 任务队列 T:存的是可被任意 agent 认领的、待执行的子任务。

整个 pipeline(论文里的 Algorithm 1)分五步走:
- Initialize:一次性把输入问题拆成初始子任务,丢进任务队列;
- RunAgents:并行 agents 各自认领子任务、独立跑,产出结果;
- Compress + Verify:结果被压缩成紧凑的 gist,校验通过后才允许写入共享上下文;
- GenerateMoreSubtasks:如果当前证据还不足以给出答案,就基于累积状态生成更多子任务,入队,再来一轮;
- Finalize:从累积的、已校验的上下文里产出最终答案。
关键在于:agent 是异步认领任务的。一个 agent 在认领之后、把结果写回 C 之前,会去检查后来的子任务是否已经让自己手头这个任务变得多余了——避免做无用功。这是中心化 MAS 做不到的。
3.2 三个机制,撑起整套设计
DeLM 能 work,靠的是三个互相配合的机制,我觉得这三个才是这篇文章真正的”私货”所在:
机制一:全局、可展开(unfoldable)的共享上下文。
基于状态的通信(state-based communication)只有在共享上下文随问题增长还能保持可用时才有意义。直接共享所有 agent 的完整文档/原始输出?那 C 很快就会爆掉,信息过载、还贵。但只共享摘要又有个风险——细节、限定条件、跨文档证据可能丢失,导致后面的 agent 推理不可靠。
DeLM 的折中是:默认存紧凑 gist,需要时再选择性地展开(unfold)成更细的摘要甚至原始证据。这种粗到细的分级访问,让协调成本压在整个问题层面,同时保留了对相关证据做细粒度检查的能力。
机制二:写入前校验(Verified Before Admission)。
这个我最喜欢。因为共享上下文是所有 agent 的通信底座,一旦错误的东西被写进 C,就会立刻被后面所有 agent 看到——一个未经核实的声明、一个有问题的状态,可能已经污染了下游的中间决策。事后再检查太贵了。
所以 DeLM 把”写入共享上下文”当成一个准入(admission)问题来处理:更新在被 admit 之前,要先用一个 LLM verifier 对照支撑证据做校验,包括 source context 和 reasoning trajectory。校验不过的,要么被拒绝、要么被重新生成,等于在通信底座前面架了一道质量闸门。
机制三:紧凑的 patch 摘要承载发现(Compact Patch Summaries)。
第三个机制是压缩。在 SWE-bench 这种场景里,直接把整个 commit history、file dump、中间编辑全共享出去,成本会暴涨、还把长 raw transcript 强塞给别人。DeLM 改成共享一个压缩后的版本(比如代码场景里的 PATCH_SUMMARY),由一个 LLM summarizer 生成,把多步调试轨迹里真正有价值的东西——证据支撑的修复、失败、约束——浓缩进可在 peer 之间共享的紧凑摘要里,避免冗余、降低成本。
4. 效果:两个差异极大的任务都拿了第一
DeLM 的实验设计挺有意思,专门挑了两个应力方向完全不同的设定:
- SWE-bench Verified:软件工程的 test-time scaling,压的是并行 + 不同推理轨迹的”聚合密集型”协调;
- LongBench-v2 Multi-Doc QA:长上下文推理,压的是跨文档的证据聚合。
4.1 SWE-bench Verified:性能更好,成本砍半
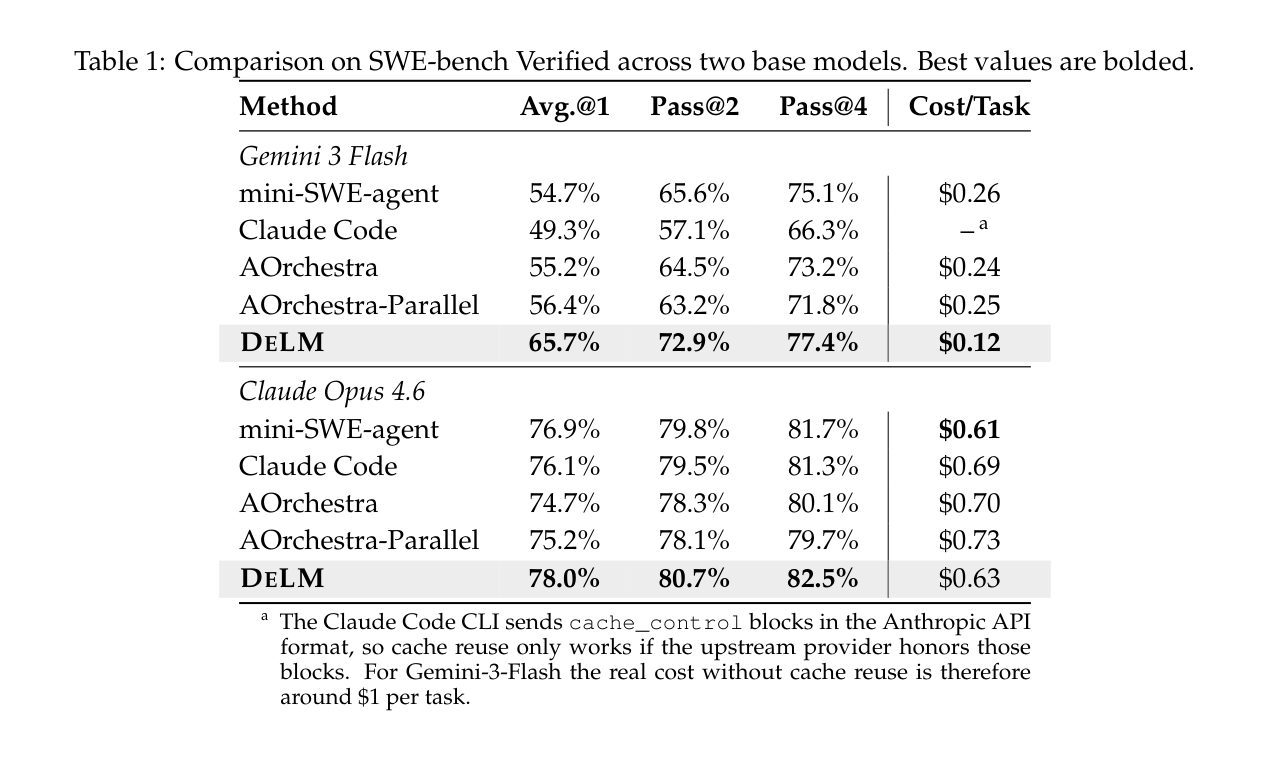
如上表,在 SWE-bench Verified 上,无论以 Gemini-3-Flash 还是 Claude Opus 4.6 为底座,DeLM 都拿到了最好的表现:
- Gemini-3-Flash 底座:DeLM 的 Avg@1 / Pass@2 / Pass@4 分别是 65.7% / 72.9% / 77.4%,最大的提升出现在 Avg@1,比最强 baseline(AOrchestra-Parallel 的 56.4%)高了 9.3 个百分点;
- 成本:DeLM 每个任务只要 $0.12,而 mini-SWE-agent、AOrchestra、AOrchestra-Parallel 普遍在 $0.24~$0.26,约等于把成本砍半。
这里有个细节很能说明问题:论文专门引入了一个 AOrchestra-Parallel 变体——它先并行起多个 agent,但把结果还是汇总过一个中心 agent。结果它比原版 AOrchestra 强,但还是不如 DeLM。这恰恰证明了:单纯”加并行”是不够的,关键在于 agent 之间能不能不经过中心节点直接通信。
在更强的 Claude Opus 4.6 上,DeLM 同样拿到 78.0% / 80.7% / 82.5%,提升幅度变小(因为底座本身已经很强了),但成本依然只比最便宜的方法贵 $0.02。
4.2 LongBench-v2:四个模型家族全员第一
换到长文档 QA,DeLM 在 GPT-5.4、Claude Sonnet 4.6、Gemini-3-Flash、DeepSeek-V4-Pro 四个前沿模型家族上全部拿到最高平均准确率,分别是 60.1% / 59.8% / 61.5% / 67.5%,对应比各家最强 baseline 高出 5.7 / 5.3 / 5.4 / 3.6 个百分点。
每个底座都涨,说明这套去中心化协调带来的好处是跨模型家族普适的,不是某个模型的运气。
4.3 消融:到底是哪个机制在起作用?
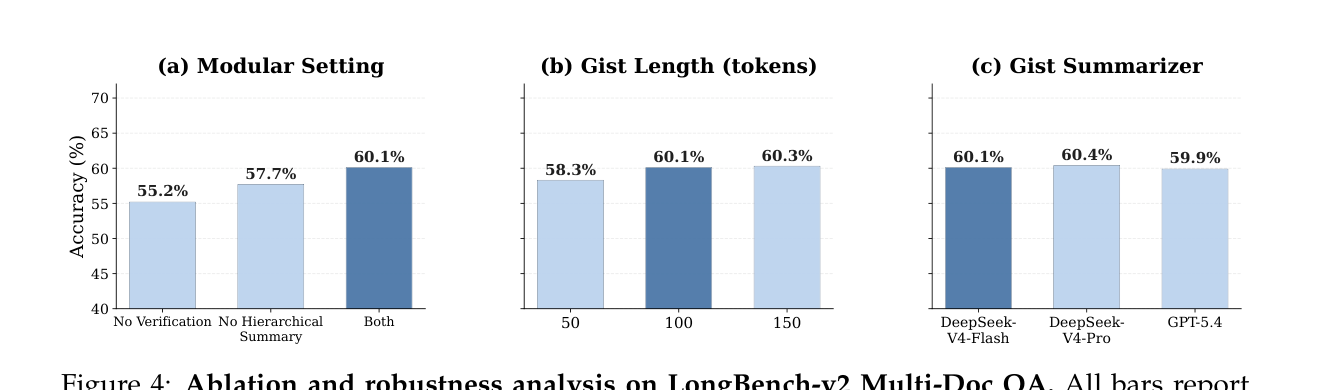
消融实验(GPT-5.4,LongBench-v2)把前面那三个机制拆开看,结论很干脆:
- 去掉写入前校验:准确率从 60.1% 掉到 55.2%——未经核实的声明会污染下游推理;
- 去掉分级摘要(hierarchical):直接崩到 37.7%——粗粒度的路由丢掉了导航到具体证据的能力,掉得更惨;
- gist 长度:从 50 token(58.3%)涨到 100 token(60.1%)后趋于平台(150 token 才 60.3%),说明 gist 不用太长,100 token 左右就够把关键信息装下了;
- 换 summarizer:DeepSeek-V4-Flash / Pro / GPT-5.4 之间几乎没差别(60.1% / 60.4% / 59.9%),DeLM 对摘要器的选择很不敏感——这点对工程落地是好消息,你可以直接用最便宜的那个。
一句话总结消融:两个组件都重要,但校验贡献了更大的增益。
5. 私货:这套设计其实”似曾相识”
写到这我想插点个人 take。读这篇的时候我一直有种强烈的既视感——DeLM 干的事,本质上还是把一个被研究透了的老问题,搬到了 agent 这个新场景。
- 中心化 MAS → 去中心化共享上下文,这不就是分布式训练里 Parameter Server → AllReduce / 去中心化梯度同步 的同一个故事吗?中心 PS 在节点多了之后成瓶颈,大家转向去中心化的 all-reduce,本质都是”别让所有通信穿过一个中心点”;
- 任务队列 + agent 自主认领 + 检查任务是否已过期,这是并发编程里经典的 work-stealing queue / actor model;
- 写入前用 verifier 把关、不过就拒绝或重生成,这跟数据库里的乐观并发控制(提交前校验)、或者 CI 里的 merge gate 是一个味道;
- gist 压缩 + 需要时 unfold,本质上是 context / KV 的分级压缩,跟我平时关心的长上下文显存问题是一脉相承的思路。
我一直觉得,agent 系统这套东西,越往后越会和系统领域几十年的积累收敛。真正的创新往往不是发明新概念,而是认出”这个新场景里的瓶颈,其实是那个老问题”,然后把对的工具搬过来。 DeLM 这篇,我会把它归到”把分布式系统的智慧正确地迁移进 LLM agent”这一类。
6. 和 RLM 互补:不是谁取代谁
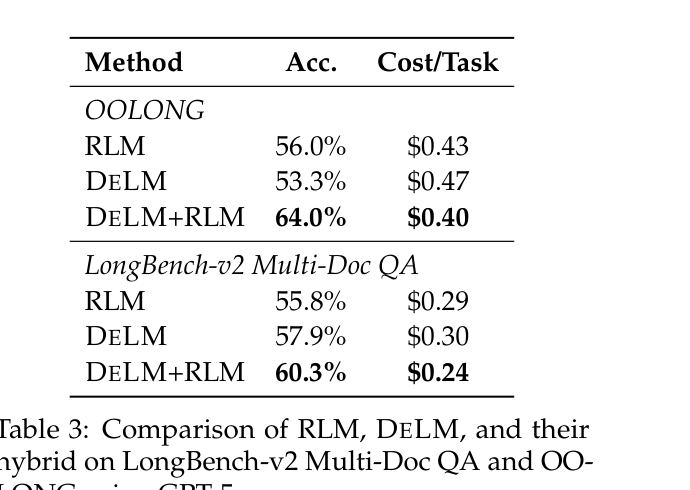
最后一个我觉得很实诚的点:论文没有把 DeLM 吹成银弹。
它专门和 RLM(Recursive Language Models,递归地用代码处理长上下文、做精确聚合)做了对比。如上表(GPT-5.5):
- 在 OOLONG(一个结构化数据处理 benchmark,需要精确计数、过滤、变换)上,DeLM 单干其实是打不过 RLM 的(53.5% vs 56.0%)——因为 OOLONG 更像一个数据处理任务,RLM 用代码做精确聚合是天然优势,而 DeLM 的自然语言协调在精确聚合上会吃亏;
- 但 DeLM + RLM 的混合方案(把 RLM 当作底层 reasoner,塞进 DeLM 的去中心化协调里)在两个 benchmark 上都拿到了最高准确率和最低成本:OOLONG 64.0% / $0.40,LongBench-v2 60.3% / $0.24。
说明 DeLM 解决的是”协调”层面的问题,RLM 解决的是”单点推理”层面的问题,两者正交、可以叠加。 这种”不抢地盘、讲清楚自己解决哪一层”的态度,我挺欣赏的。
7. 一点 take
总的来说,DeLM 这篇我读下来最大的收获不是某个具体数字,而是它把”多 agent 越加越慢”这个大家隐隐感觉到、但说不清的现象,精确地归因到了中心化通信这一个点上,然后给出了一个干净的解法:共享、已校验、可展开的上下文 + 任务队列。
如果你也在搭 agent pipeline、被那个越来越臃肿的 orchestrator 折磨过,这篇值得一读——至少它给了你一个清晰的框架去想”我的瓶颈到底在哪一层”。
当然也有可以挑的地方:写入前的 LLM verifier 本身也是成本和延迟,论文虽然给了成本数据,但这个 verifier 在更大规模 agent 数下会不会反过来成为新的瓶颈,我觉得是个开放问题。欢迎评论区一起聊聊你们踩过的 MAS 的坑。