arXiv'26 | Self-Harness:让 Agent 自己改自己的 harness,pass rate 最高翻倍
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

Self-Harness:让 Agent 自己改自己的 harness,pass rate 最高翻倍
1. 前言
你有没有想过,你的 AI Agent 到底是被谁”调教”出来的?
做过 Agent 开发的应该都有体感——一个 LLM 能不能干活,只有一半取决于模型本身。另一半取决于你包在它外面那层东西:system prompt 怎么写、tools 怎么配、出错了走什么恢复逻辑、context 怎么管理。这层东西,业内现在越来越多叫它 harness。
同一个模型,换一套 harness,性能能差出一倍。这不是夸张——Claude Code、Codex、OpenHands,本质上都是不同的 harness 套在相同或相似的模型上。
但问题来了:这层 harness 目前全靠人肉工程。 你反复跑 case,看 trace,发现”模型老是忘记写输出文件”,手动加一行 instruction;发现”模型死循环了”,手动加一个 max retry。这种模式对一个模型还凑合,对十个不同 backend 呢?根本不 scale。
更离谱的是,不同模型的”坏习惯”完全不同。MiniMax 容易忘记创建 artifact,Qwen 容易在 edit 失败后把文件删了,GLM 容易丢环境变量。你没法写一套通用 harness 解决所有模型的问题——这本质上是 model-specific 的。
今天要聊的这篇来自上海 AI Lab 的工作——Self-Harness——提了一个思路:让 Agent 自己改自己的 harness。不需要人类工程师,也不需要一个更强的外部模型来指导。
2. 三种 harness 改进范式
先交代下背景。目前 harness 改进存在三种范式:
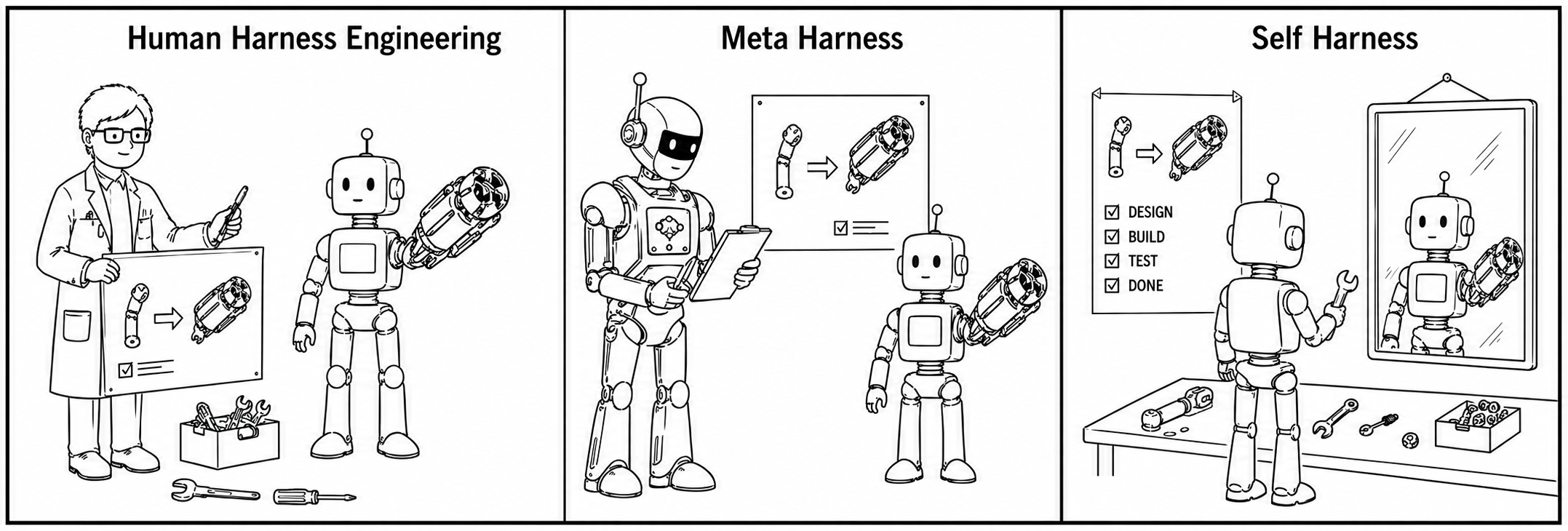
Human Harness Engineering:人类专家手动检查 trace、改 prompt、加 tool——就是我们现在在做的事。问题是不 scale。
Meta-Harness:用一个更强的外部模型去优化弱模型的 harness。比如用 Claude 4 去帮 Qwen3.5 改 harness。问题是:对 frontier model 来说没有”更强的”了,而且外部模型不一定理解目标模型的真实 failure mode。
Self-Harness(本文):让模型自己改自己的 harness。用同一个固定模型,基于自己执行失败的证据,提出 harness 修改方案,再用 regression test 验证。
这也是整个 Agent 工程化方向的一个核心趋势:从”人调 prompt”到”模型调 harness”。
3. 方法:三步自改进循环
Self-Harness 的核心 idea 很朴素——一个三步迭代循环:
3.1 Weakness Mining:从 trace 里挖 failure pattern
第一步不是直接改 harness,而是先搞清楚模型到底在哪里反复犯错。
具体做法:把模型在一组 held-in task 上跑一遍,收集所有失败的 execution trace,然后按 failure signature 聚类。一个 failure signature 包含三个维度:
- Verifier 拒绝的原因(timeout?missing artifact?assertion failure?)
- Agent 行为与该失败的因果关系(直接导致?间接贡献?)
- 背后的抽象行为机制(death loop?忘记创建文件?环境变量丢失?)
关键点:不是看单个 case 挂了,而是找”这类问题反复挂在同一个机制上”。两个 case 可能都 timeout 了,但一个是因为死循环,另一个是因为等外部下载——它们需要不同的 harness fix。
3.2 Harness Proposal:同一个模型提修改方案
第二步用同一个模型(不是更强的模型!),基于聚类出来的 failure pattern,生成多个并行的 harness 修改候选。
每个候选有几个硬约束:
- 必须绑定到一个具体的 failure mechanism
- 只能改一个具体的可编辑表面(instruction、tool config、middleware 等)
- 多个候选之间必须 materially distinct——不能换个说法重复同一个修改
- 最小化编辑:不能大改架构,只做 narrow change
3.3 Proposal Validation:regression test 保驾护航
第三步是验证。改完的 harness 不能光解决已知问题,还不能把之前能跑过的搞挂。
接受规则很保守:
- held-in 和 held-out 两个 split 都不能降
- 至少一个 split 要提升
- 如果只是”在 A 上涨了但 B 上跌了”——不接受
多个通过验证的候选可以 merge 到下一版 harness。没通过的不会被采用,但会被记录下来供后续参考。
4. 实验:三个模型,三套不同的进化路径
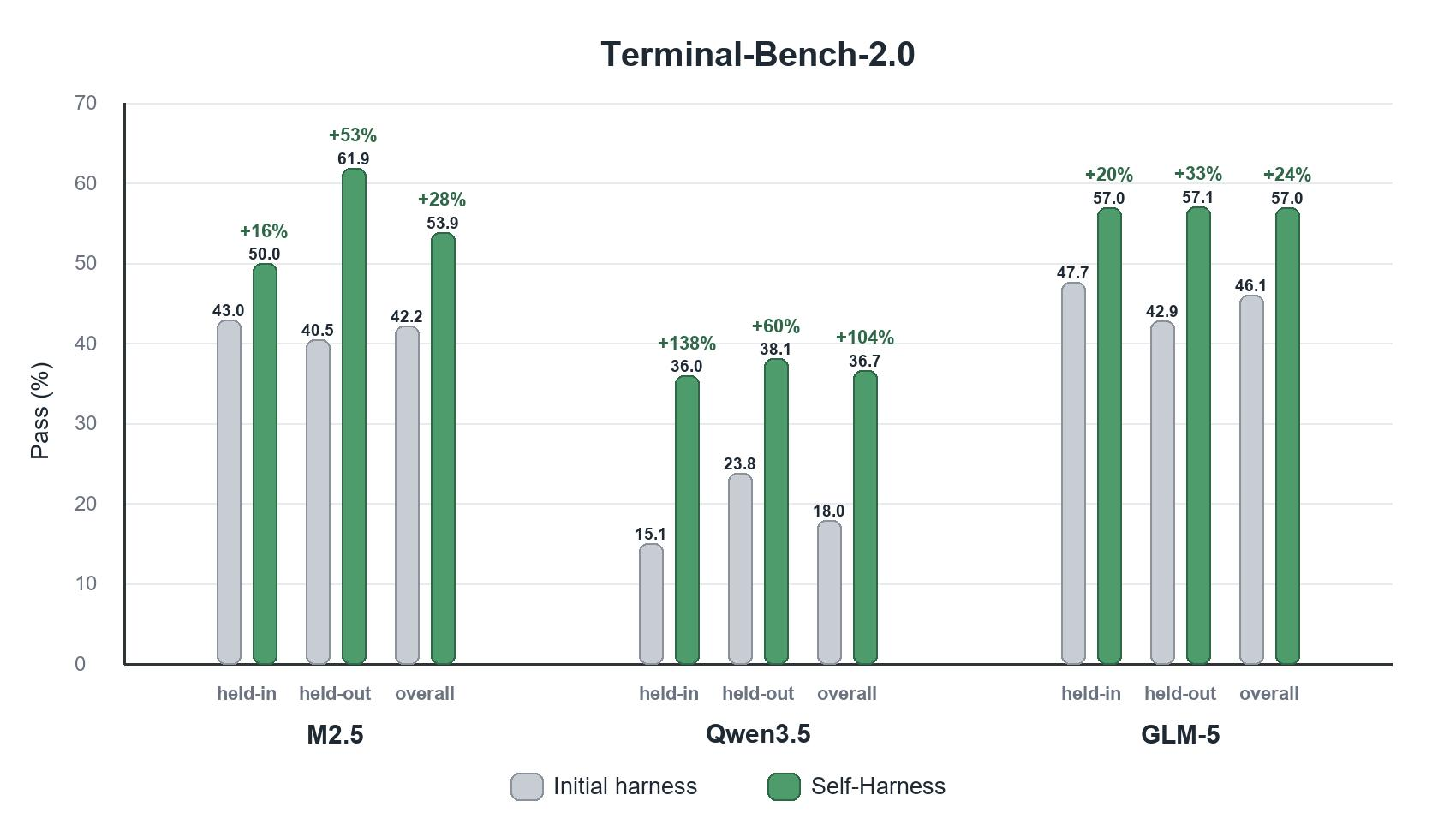
他们在 Terminal-Bench-2.0(89 个容器化终端任务)上做了实验,用了三个差异很大的模型:MiniMax M2.5、Qwen3.5-35B-A3B、GLM-5。初始 harness 是一个极简的 DeepAgent baseline——只有一段简短的 system prompt 加默认的文件和 shell 工具。
结果如下:

数字说话:
| 模型 | held-in(初始→最终) | held-out(初始→最终) | 相对提升 |
|---|---|---|---|
| MiniMax M2.5 | 43.0% → 50.0% | 40.5% → 61.9% | +53% |
| Qwen3.5-35B-A3B | 15.1% → 36.0% | 23.8% → 38.1% | +60%(held-out),+138%(held-in) |
| GLM-5 | 47.7% → 57.0% | 42.9% → 57.1% | +33% |
几个关键观察:
- held-out 也涨了——说明改进不是 overfit 到已知 case,而是捕捉到了通用的行为机制
- 三个模型都涨了——证明方法不依赖特定模型能力
- Qwen3.5 的提升最大(138%)——说明初始 harness 越不适配模型特点,Self-Harness 的改进空间越大
5. 最有意思的部分:不同模型进化出了完全不同的 harness
这篇文章最让我觉得有意思的地方,不是那几个 percentage point 的提升,而是三个模型进化出来的 harness 长得完全不一样。
如下图是 Qwen3.5 经过 Self-Harness 后保留的四个 code-level diff:

逐个看:
MiniMax M2.5 学会了什么:
- “先建输出文件再干活”——因为它老是探索到最后忘记 write artifact 就 timeout 了
- 限制 tool call 总数——防止进入”无效 tool-use loop”
- 更小心地处理 structured tool content 的 schema
Qwen3.5 学会了什么:
- Dependency precheck——执行前先检查 Python module 是否存在
- 不重复执行完全相同的失败命令(”do not retry the exact same command with the exact same parameters”)
- 限制连续 explore 步数不超过 3 步就要做 change
- Tool error 后触发 artifact recovery middleware——这个最骚,它自己给自己造了一个 middleware,当检测到 tool error 时自动注入”你必须立即创建缺失的 artifact”这条 system prompt
GLM-5 学会了什么:
- 让环境变量和 PATH 修改跨 shell session 持久化——因为它每次开新 shell 都丢状态
- 从”无止境的 exploration”转向”实现 + 测试”——给自己设了一个阶段切换点
本质上,不同模型有不同的”坏习惯”,需要不同的 harness 来矫正。 MiniMax 的核心问题是”做太多探索忘了交作业”,Qwen 的核心问题是”edit 失败后走向自毁”,GLM 的核心问题是”环境状态不持久”。人类手动做这事成本极高,但让模型自己诊断自己的毛病、自己开药方,这条路看起来是通的。
6. Case Study:从失败到成功的行为对比
如下图展示了 MiniMax M2.5 在一个 count-dataset-tokens 任务上的 before/after 对比:

左边(初始 harness):模型找到了 metadata 配置,但之后继续无意义的 dataset exploration,最终 timeout 没有写出 answer.txt。
右边(改进后 harness):模型定位到 metadata-backed subset,计算 token count,立即写 /app/answer.txt,然后 read back 验证。
这个行为变化的根源就是 Self-Harness 给 bootstrap instruction 加了一条:”identify the required output artifact and create an initial version as early as possible”。一行改动,一类问题解决。
7. 局限与思考
当然,这篇的局限也很明确:
- 在一个固定 benchmark 上做的——Terminal-Bench-2.0 只有 64 个 task,promotion rule 可能对这个规模很敏感
- Edit 是 bounded 的——只能改声明好的 editable surfaces,不能动模型参数或工具实现
- 不是开放式自我进化——它没法给自己加新 tool 或改变控制架构,只是在已有框架内微调执行策略
- 依赖 verifier 质量——如果 verifier 本身有噪声,promotion gate 会出问题
但作为一个 proof of concept,它回答了一个关键问题:固定参数的模型能不能通过改 harness 把自己变强?能。
我个人的 take:这条路和 Meta-Harness(外部模型优化)不矛盾。对于 frontier model,Self-Harness 是唯一选择(没有更强的了);对于中小模型,也许两者结合效果更好。另外,Self-Harness 的 weakness mining + proposal + validation 这个 pattern,其实可以迁移到很多其他”系统配置自优化”的场景——你有 trace、有 verifier、有可编辑表面,你就能跑这个循环。
8. 总结
一句话概括:Self-Harness 让 LLM Agent 不再只是被动接受人类设计的 harness,而是能基于自己的执行失败证据,自己提出、验证、并接受 harness 修改。
核心贡献:
- 提出了 Self-Harness 范式:模型自己改自己的 harness
- 三步循环:Weakness Mining → Harness Proposal → Proposal Validation
- 在三个不同模型上都有效,held-out pass rate 最高相对提升 138%
- 定性分析表明不同模型进化出不同的 harness——不是加了一堆通用废话,而是针对性地解决了 model-specific 的行为缺陷
这也是整个 Agent 工程化方向的一个趋势信号:harness 不再是写死的,它可以演化。从 prompt engineering 到 context engineering 到 harness engineering,下一步可能就是 harness self-evolution。
欢迎评论区讨论:你觉得让 Agent 自己改自己的 harness,边界在哪里?