arXiv'26 | Mirage:把世界模型的 3D 记忆搬进 Latent Space,快 10 倍还省 55 倍显存
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

Mirage:把世界模型的 3D 记忆搬进 Latent Space,快 10 倍还省 55 倍显存
1. 什么是世界模型?从 LLM 到”脑中模拟器”
你有没有想过,人类为什么能在脑子里”预演”未来?
比如你在一个陌生的房间里走了半圈,转身回来——你会”预期”看到刚才路过的沙发、桌子还在原位。你甚至可以闭着眼睛想象:如果我从这个角度看过去,那个柜子应该被墙挡住了。
这种能力,本质上就是你大脑里维护了一个世界的内部模型:它记住了场景的空间结构,能根据你的”动作”(移动、转头)预测下一步会看到什么。
世界模型(World Model)就是 AI 试图复刻这种能力的尝试。
1.1 世界模型的正式定义
简单来说,世界模型是一个系统,它能够:
- 观察当前环境状态(一帧图像、一段视频)
- 记忆已经看过的场景信息
- 预测/生成在给定动作(如相机轨迹)下的未来观察
用数学来说,给定初始帧 $I_0$ 和一条相机轨迹 ${(\mathbf{E}t, K_t)}$(位姿+内参),世界模型需要生成一系列多视角一致的帧 ${I_t}{t=1}^T$。
这跟纯粹的”视频生成”有什么区别?核心区别在于 3D 一致性。普通的视频生成模型(如 Sora、Wan)可以生成漂亮的视频,但如果你让相机绕回起点,生成的画面大概率跟开头完全对不上——因为它没有维护一个持久的 3D 空间表示。
1.2 世界模型的应用场景
世界模型为什么重要?因为它是很多下游应用的底座:
- 自动驾驶模拟:给定车辆轨迹,生成逼真的驾驶场景视频用于训练和测试
- 游戏/交互环境生成:玩家在虚拟世界里自由探索,系统实时生成一致的新场景
- 机器人导航规划:机器人在脑中”预演”路线,预判会遇到什么
- 3D 内容创作:从单张图片出发,探索式地生成完整的 3D 场景
1.3 视频世界模型的演进路线
近年来,随着 video diffusion model 的突破(Sora、CogVideoX、Wan2.1 等),研究者开始把这些强大的视频生成器当作”世界模拟器”来用。大致经历了三个阶段:
阶段一:纯视频生成器
直接用 video diffusion model 生成视频,可以条件在相机轨迹上。问题是:没有持久记忆。每次生成只看有限的时间窗口,超出窗口的信息就丢了。相机走远了再回来,场景大概率”漂”了。
阶段二:带 RGB 点云记忆的世界模型
为了解决 3D 一致性问题,一系列工作(WonderJourney、WonderWorld、Voyager、Spatia 等)给视频生成器加了一个持久的 RGB 点云作为空间记忆:
- 把每一帧用深度估计 lift 成 3D 点云
- 点云存储每个点的 3D 坐标 + RGB 颜色
- 生成新视角时,先把点云渲染成目标视角的 RGB 图像,再 encode 成 latent 送给 diffusion backbone
这确实有效——有了 3D 锚点,相机回访时能”记住”之前看到了什么。
但问题来了。
1.4 RGB 点云记忆的核心瓶颈
这也是整个领域在 Mirage 之前面临的核心矛盾:
video diffusion model 在 latent space 工作,但空间记忆在 pixel space 工作。每生成一帧,都要做一次”latent → pixel → latent”的来回折腾。
具体来说:
- 计算代价爆炸:每一步 conditioning 都要先把百万级的点云渲染成全分辨率 RGB 图像,再用 VAE encoder 编码回 latent。渲染和编码的分辨率是 pixel 级的(如 704×1280),而 diffusion backbone 只需要 latent 级的(如 44×80)。相当于每步都做了一大堆无用功。
- 信息损失:latent → pixel → latent 的 round trip 并不是无损的。VAE 重建有误差,光栅化有 artifacts,可见性有空洞。原本 latent 里丰富的语义/纹理特征,经过 RGB 这一趟就”打了折”。
- 内存随 rollout 线性增长:点云越来越大,渲染越来越慢,到最后 GPU 直接 OOM。
一句话总结:你的生成器在 latent 世界里干活,但你非要让它的记忆在 pixel 世界里存取,来回倒腾既慢又损。
这就是 Mirage 要解决的核心问题。
2. Mirage:Latent Spatial Memory
今天想聊的这篇工作,核心 idea 出奇地自然:
既然 diffusion backbone 消费的是 latent,那空间记忆为什么不直接存 latent?
如下图,上半部分是之前的 RGB 点云方案:存颜色 → 渲染成图 → 再 encode 回 latent;下半部分是 Mirage 的 latent spatial memory:存 latent 特征 → 直接投影到目标视角的 latent grid 上。省掉了 pixel space 的来回。
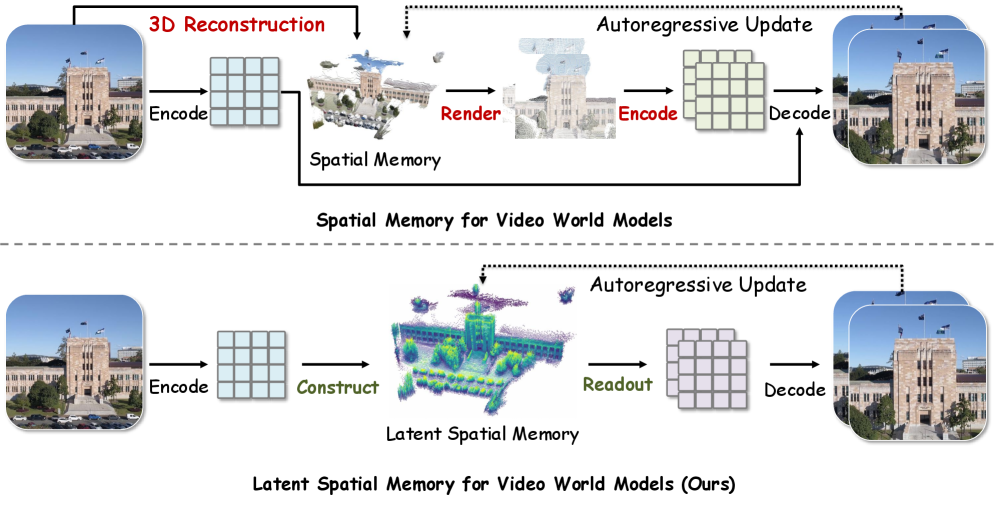
2.1 Latent Spatial Memory 的定义
Mirage 的记忆不再是 $\mathcal{M}_{\text{rgb}} = {(\mathbf{p}_i, \mathbf{c}_i)}$(坐标 + 颜色),而是:
\[\mathcal{M} = \{(\mathbf{p}_i, \mathbf{f}_i)\}, \quad \mathbf{p}_i \in \mathbb{R}^3, \quad \mathbf{f}_i \in \mathbb{R}^C\]每个点存的是一个 $C=48$ 维的 latent feature vector(对应 Wan2.2 的 VAE latent channel 数),而不是 3 维的 RGB。
这意味着什么?记忆里存的是 diffusion model 的”母语”——跟 backbone 直接对接,不需要翻译。
2.2 记忆的构建:Depth-Guided Back-Projection
构建过程和 RGB 方案类似,只是存的内容不同:
- 输入帧 $I$ 通过 VAE encoder 得到 latent tensor $\mathbf{z} \in \mathbb{R}^{C \times h \times w}$
- 估计深度图 $D$,下采样到 latent 分辨率
- 每个 latent cell $(u,v)$ 通过 pinhole 反投影到世界坐标系:
- 对应的 latent token $\mathbf{F}_{uv} = \mathbf{z}[:,v,u]$ 存入记忆
关键点:整个 lifting 在 latent 分辨率进行(44×80),不是 pixel 分辨率(704×1280)。空间点数直接少了 $s^2 = 16^2 = 256$ 倍。
2.3 记忆的读取:Latent-Space Projection
读取时同样高效——目标视角下的 conditioning signal 通过一次 latent 分辨率的投影就得到了:
- 把记忆中所有点投影到目标相机的 latent grid 上
- 每个 cell 保留深度最近的点(z-buffering)
- 取出对应的 latent token 组成 target-view latent tensor $\hat{\mathbf{z}}_t$
- 同时生成 visibility mask $\mathbf{m}_t$ 标记哪些位置有信息
整个 readout 不涉及任何 pixel 空间操作。没有渲染,没有 VAE encode。就是一次 latent 分辨率的投影。
3. Mirage 的完整流程
如下图,Mirage 以 chunk-by-chunk 的方式自回归生成长视频,每个 chunk 经历三步循环:
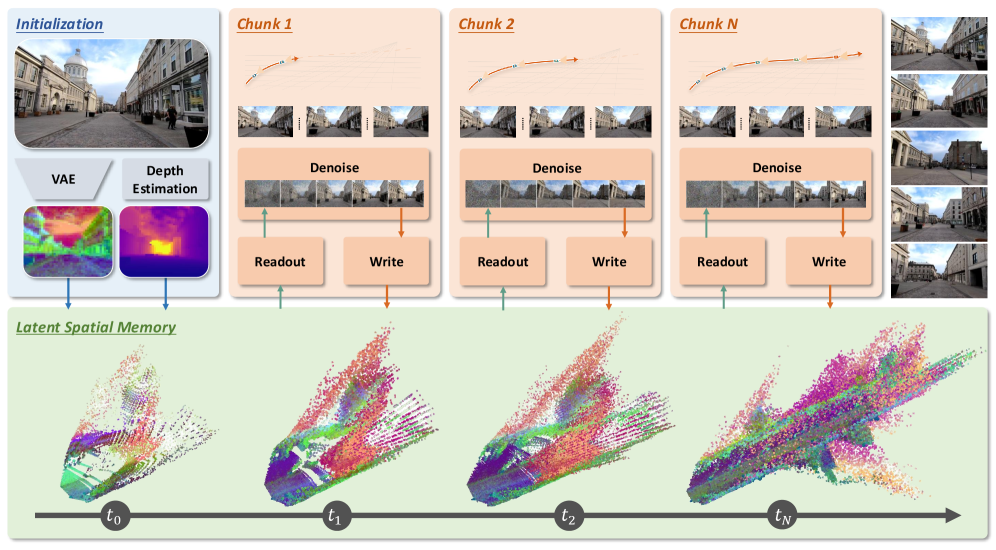
3.1 Initialize → Readout → Update 循环
Step 1:初始化记忆
- 对初始帧 $I_0$ encode 得到 latent,估计深度,back-project 到 3D → 得到初始 cache $\mathcal{M}$
Step 2:Readout + Denoising(逐 chunk)
- 把 $\mathcal{M}$ 投影到当前 chunk 每个目标视角 → 得到 latent conditioning tensors
- 通过 ControlNet-style 的 side branch 注入 diffusion backbone
- Backbone 在 latent space 做 denoising → 生成当前 chunk
Step 3:Cache Update
- 对生成的帧估计深度、re-encode 为 latent
- 用分割模型检测动态物体和天空,排除这些区域
- 将静态区域的 latent tokens back-project 进记忆
然后回到 Step 2,处理下一个 chunk。
3.2 关键设计细节
ControlNet-style 注入:readout 的 latent tensor 通过一个跟 backbone 结构对齐的 side branch 注入。因为 readout 已经在 backbone 的 latent space 里了,所以不需要额外的 bridging encoder——这是 RGB 方案做不到的。
动态物体过滤:用 Qwen3-VL 做开放词汇实体检测 + SAM3 做分割,把移动物体和天空从记忆更新中排除。因为这些东西的 geometry 不靠谱,放进 persistent cache 会污染记忆。
两阶段训练:
- 第一阶段冻结 backbone 和 VAE,只训练 side branch
- 第二阶段加 rank-64 LoRA 在 self-attention 上,跟 side branch 联合优化
这种策略避免了 backbone 在早期适配一个还不成熟的 conditioning signal。
4. 实验结果
4.1 WorldScore Benchmark
WorldScore 是一个专门评估 world generation 的 benchmark,涵盖可控性、一致性、质量、运动四大维度。Mirage 在 Average Score 上达到 70.36,超过所有对比方法:
| 方法 | Average | Static | Dynamic | 3D Cons | Photo Cons |
|---|---|---|---|---|---|
| WonderJourney | 54.19 | 63.75 | 44.63 | 80.60 | 79.03 |
| Voyager | 66.08 | 77.62 | 54.53 | 81.56 | 85.99 |
| Spatia | 69.73 | 72.63 | 66.82 | 86.40 | 89.10 |
| Mirage | 70.36 | 73.60 | 67.11 | 92.21 | 93.95 |
特别注意 3D Consistency 和 Photometric Consistency——Mirage 分别达到 92.21 和 93.95,大幅领先 RGB cache 方案。这直接验证了 latent spatial memory 比 RGB 点云能更好地保持几何一致性。
4.2 RealEstate10K
在 RealEstate10K 上,Mirage 在 Novel View Synthesis 和 Closed-Loop(相机走一圈回来的一致性测试)上均达到最优或接近最优:
| 方法 | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR_C↑ | SSIM_C↑ |
|---|---|---|---|---|---|
| ViewCrafter | 15.78 | 0.580 | 0.396 | 14.79 | 0.481 |
| Voyager | 17.79 | 0.636 | 0.297 | 17.66 | 0.540 |
| Spatia | 18.58 | 0.646 | 0.254 | 19.38 | 0.579 |
| Mirage | 18.38 | 0.779 | 0.250 | 20.05 | 0.825 |
Closed-Loop 指标尤其有说服力——相机绕了一圈回来,Mirage 的 SSIM_C 达到 0.825,远超 Spatia 的 0.579。这说明 latent 记忆真的在长距离 rollout 下保持了场景一致性。
4.3 效率:这才是 Latent Spatial Memory 的杀手锏
如下图,随着 rollout 长度增加,Mirage 的每帧 cache 读取时间和内存占用几乎不增长,而 RGB 方案则爆炸式上升:
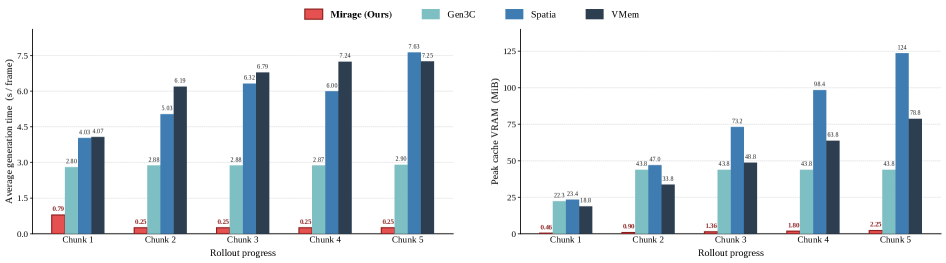
具体数字:
- 端到端生成速度:比 RGB cache 快 10.57×
- 3D cache 显存占用:比 RGB 方案少 55×
为什么差这么多?因为:
- RGB 方案每步要在 $H \times W$(如 704×1280)分辨率做光栅化 + VAE encode
- Mirage 只需要在 $h \times w$(如 44×80)分辨率做一次投影
- cache 本身的 footprint 也小了 $s^2 = 256$ 倍(latent stride 16)
而且这个差距随着 rollout 变长会越来越大——RGB 方案最终会 OOM,Mirage 可以轻松完成。
4.4 消融实验
| 变体 | Avg | 3D Cons | Photo Cons |
|---|---|---|---|
| Mirage (full) | 70.36 | 92.21 | 93.95 |
| 换成 RGB 点云 | 67.71 | 90.75 | 91.10 |
| Feature Upsample | 60.85 | 84.90 | 79.81 |
| 去掉动态物体过滤 | 61.20 | 80.88 | 76.10 |
| 单阶段训练 | 63.18 | 87.11 | 84.47 |
几个关键结论:
- Latent vs RGB:同样的 backbone + 训练策略,仅把 cache 从 latent 换成 RGB,Average Score 从 70.36 降到 67.71。说明 RGB round trip 确实损失了信息。
- 动态物体过滤很重要:去掉后 3D Consistency 从 92.21 暴降到 80.88。移动物体的 stale 几何如果留在 cache 里,后面生成时会被错误地 splat 回来。
- 两阶段训练有效:让 side branch 先稳定了再解锁 LoRA,比一起从头训收敛更好。
5. 局限性与思考
动态物体没有被记忆:当前方案直接把动态物体从 cache 中排除了。这意味着如果场景里有个人走过,相机回来时那个人不会”被记住”。这是一个简化假设——persistent memory 目前只服务于静态几何。
对深度估计的依赖:整个 lifting/update 依赖 metric depth。虽然消融实验显示换不同 depth estimator 影响不大(因为 ControlNet 把 readout 当作 soft hint),但在极端场景下深度估计失准还是会影响 cache 质量。
我的 take:
这篇工作的核心贡献其实是一个很自然的 insight——空间记忆应该和生成器在同一个表示空间。之前的 RGB 点云方案之所以又慢又损,本质上是因为”存储空间”和”工作空间”不匹配。Mirage 把记忆搬进 latent space,从根源上消除了 pixel-latent 的来回折腾。
10× 加速和 55× 内存节省不是靠什么 trick 堆出来的,是 表示层面的结构性改进 带来的自然结果。这种”对问题本质的重新思考”往往比在现有框架上做 engineering optimization 更有效。
6. 总结
| 维度 | RGB 点云方案 | Mirage(Latent Spatial Memory) |
|---|---|---|
| 记忆内容 | 3D 坐标 + RGB 颜色 | 3D 坐标 + Latent Feature |
| Readout 方式 | 渲染 → VAE Encode | 直接 latent 投影 |
| 每步操作分辨率 | Pixel ($H \times W$) | Latent ($h \times w$) |
| 端到端速度 | 1× | 10.57× |
| Cache 显存 | 1× | 1/55 |
| 信息保真 | 有 VAE 重建损失 | 无损(native latent) |
| 3D Consistency | 86-91 | 92.21 |
一句话:世界模型的 3D 记忆,应该说”latent 的语言”,而不是 pixel 的语言。
Mirage 用一个干净的 idea 把 video world model 的效率和质量同时拉上来了。对于做 LLM/视频生成/3D 相关的同学,这个”把记忆搬进 native representation space”的思路很有借鉴意义。
Project Page: aka.ms/latent-spatial-memory