arXiv'26 | FlashMemory-DeepSeek-V4:用 13.5% 的显存干 100% 的活,超长上下文推理的 less is more
FlashMemory-DeepSeek-V4:用 13.5% 的显存干 100% 的活,超长上下文推理的 less is more
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

原文:FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
1. 前言
你有没有想过,当一个 LLM 在处理一段 500K token 的超长上下文时,GPU 上那些 KV cache 里有多少是真正被用到的?
答案是:90% 以上的请求,光靠最后 8K token 就能准确回答。
这就是这个领域最核心的矛盾——你为了应对那 10% 的”真需要回忆全文”的情况,不得不把整个 KV cache 全量加载到 GPU 显存里。500K token 的 context,KV cache 动辄 1.8GB+,而大部分时候你只需要其中很小一部分。
传统做法要么”全部加载”(浪费显存),要么”sliding window 只看最近的”(丢掉远处关键信息)。这两个极端,都不是答案。
今天想和大家聊聊这篇来自腾讯 AI Lab 的工作——FlashMemory-DeepSeek-V4——它在 DeepSeek-V4 的架构上做了一个非常优雅的改动:用一个超轻量的 Neural Memory Indexer,提前预测未来 64 步需要哪些历史 KV chunk,按需从 CPU 加载到 GPU,其余的全部留在 CPU 冷存储。
结果:GPU 显存占用降到 baseline 的 13.5%,准确率反而还涨了 0.6%。 对,没看错——”less is more”。500K context 下显存压缩超过 90%。
但要读懂这篇工作,你得先搞明白 DeepSeek-V4 本身的 attention 架构设计。这部分我会花较多篇幅讲清楚,因为不懂 V4 的底层,后面的 FlashMemory 就是空中楼阁。
2. DeepSeek-V4 的 Hybrid Attention 架构
先交代下背景。DeepSeek-V4 是 DeepSeek-AI 2026 年发布的最新一代大模型,分两个规格:
- DeepSeek-V4-Pro:1.6T 参数(49B 激活),MoE 架构
- DeepSeek-V4-Flash:284B 参数(13B 激活),MoE 架构
两者都支持 100 万 token 的上下文窗口。
这么长的 context,如果用普通的 full attention,KV cache 的线性增长会直接把 GPU 撑爆。DeepSeek-V4 的核心创新就在于它的 Hybrid Attention Architecture——把 attention 层分成两种类型,各自承担不同的任务:
2.1 HCA(Heavily Compressed Attention)
HCA 层的压缩比是 128:1。
什么意思?假设原始 context 有 128K token,经过 HCA 压缩后,变成大约 1K 个 compressed entry。每个 entry 代表 128 个连续 token 的”语义摘要”。
HCA 层的作用是维持全局上下文感知——即使在超长序列下,模型也能通过这些高度压缩的 entry 感知到远处发生了什么。代价是精度有损:你知道”远处发生了某件事”,但不知道具体细节。
这些 HCA chunk 体积极小(128:1 压缩),始终保留在 GPU 显存中,不会被 offload。
2.2 CSA(Compressed Sparse Attention)
CSA 层是 DeepSeek-V4 的”精细回忆”通道。
和 HCA 不同,CSA 的压缩比低得多(保留更多 token 级细节),但不会对所有历史 token 都做 attention——它用一个 Lightning Indexer 来选择性地关注最相关的那些。
Lightning Indexer 的工作方式是:
- 把当前 query token 投射到一组低秩 indexer query 上
- 和所有历史 compressed entry 的 indexer key($K^{IComp}$)做内积
- 用 ReLU 激活 + Top-$k$ 选取分数最高的若干历史 entry
- 只对这 Top-$k$ 个 entry 做完整的 Multi-Query Attention
这样,CSA 层不需要对全量历史做 attention,只扫描 Top-$k$ 个最相关的 chunk。
2.3 MLA(Multi-head Latent Attention)
DeepSeek-V4 延续了 V3 的 MLA 设计。核心思路是对 query 和 key-value 都做低秩分解:
- Query 先经过 down-projection 到一个低维 latent space(
q_lora_rank = 1536),再 up-project 回多头 - Key-Value 也做了类似的压缩,这样 KV cache 存储的是压缩后的 latent 向量,而不是原始的高维 KV
这个设计直接决定了 DeepSeek-V4 的 KV cache 本身就比标准 MHA 模型小很多——但在 100 万 token 下,即便压缩后,依然是线性增长的。
2.4 整体 KV cache 开销
在 1M token 上下文设置下,DeepSeek-V4-Pro 相比 V3 只需要:
- 27% 的单 token 推理 FLOPs
- 10% 的 KV cache
但即便如此,CSA 层的 KV cache 在 500K token 下仍然占据 1.87GB(8×H20 部署环境)。而且这个占用是不管你当前 token 用不用那些远处的 context,都全部加载。
这就是 FlashMemory 要解决的问题。
3. FlashMemory 的核心思路:Lookahead Sparse Attention
FlashMemory 的设计理念是一句话:不要等用到的时候才去回忆,提前预测未来 64 步需要什么。
如下图,左侧是 DeepSeek-V4 原生的 CSA pipeline(黑线),右侧是 FlashMemory 提出的 LSA(Lookahead Sparse Attention)机制(红线):
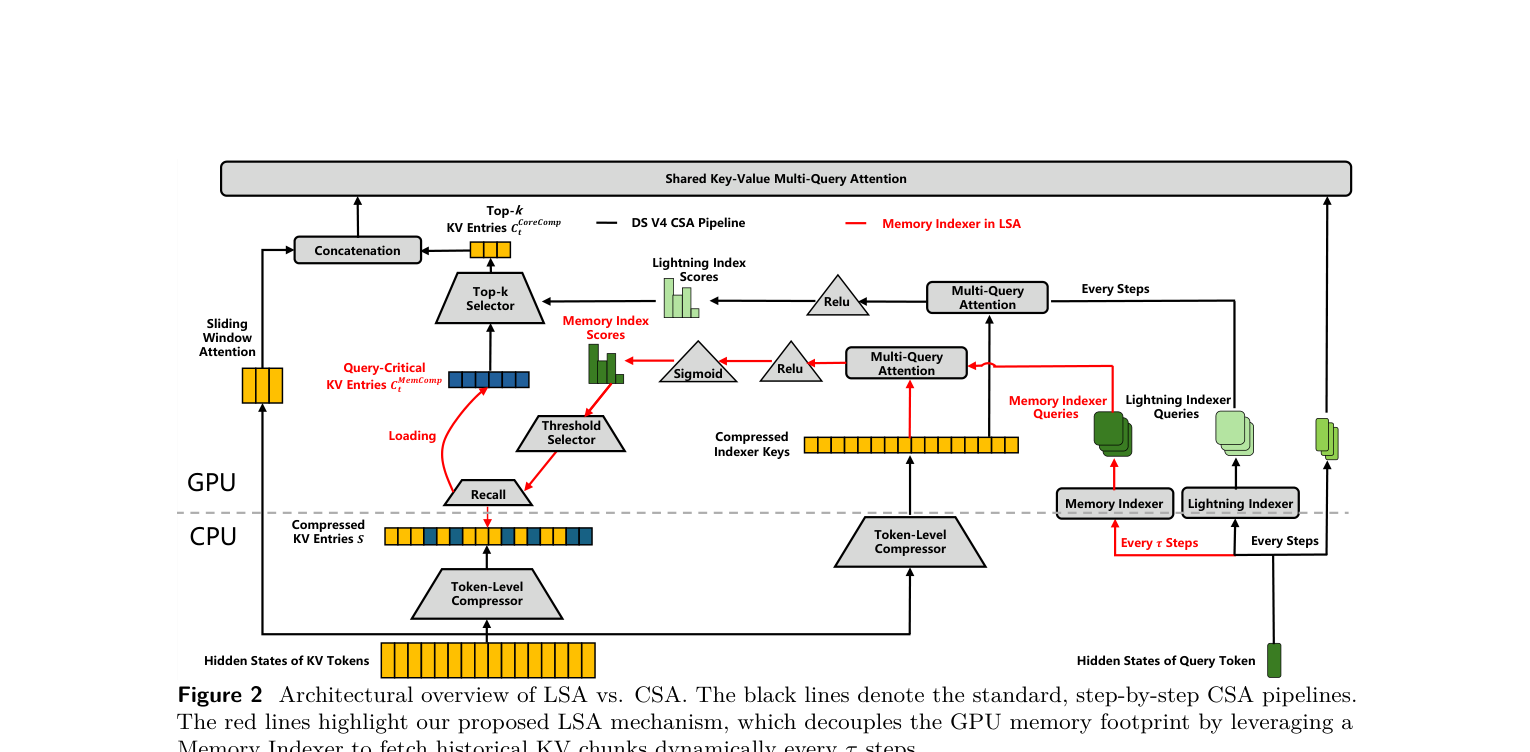
原生 CSA 的流程是:每一步 decode 都用 Lightning Indexer 做一次 Top-$k$ 选择,从全量 compressed KV 中选出最相关的 entry。这意味着所有历史 compressed KV 都要常驻 GPU 显存,否则 Lightning Indexer 没法实时做选择。
LSA 的改动看起来很小,但影响是根本性的:
- 引入一个 Memory Indexer,每隔 $\tau = 64$ 个 decoding step 触发一次
- Memory Indexer 预测:未来 64 步可能会用到哪些历史 compressed KV chunk
- 只把这些被预测为”关键”的 chunk 从 CPU cold pool 加载到 GPU
- 在这 64 步内,原生的 Lightning Indexer 在这个缩小的搜索范围内做正常的 Top-$k$ attention
这样一来,绝大部分历史 KV cache 就可以安全地留在 CPU 内存里,不占 GPU 显存。
3.1 Memory Indexer 的数学
Memory Indexer 复用了 DeepSeek-V4 原生 Lightning Indexer 的架构(低秩投影 + 内积打分),只做了一个关键改动:
把 ReLU + Top-$k$ 换成了 Sigmoid + 阈值。
原生 Lightning Indexer 的行为是:
- ReLU 激活后取分数最高的 Top-$k$ 个 entry(固定数量)
Memory Indexer 的行为是:
- Sigmoid 激活,把分数映射到 $(0, 1)$ 区间
- 设定阈值 $\geq 0.5$ 的所有 entry 都被认为”关键”
- 关键 entry 从 CPU 拉到 GPU
为什么用 Sigmoid + 阈值而不是 Top-$k$?因为不同的 query,真正需要的历史 chunk 数量是动态变化的。有些 token 只需要 local context 就够了(0 个远处 chunk),有些 token 需要综合全文(大量 chunk)。Top-$k$ 的固定数量无法表达这种差异。
具体公式:给定 decoding step $t$,当前 hidden state $\mathbf{h}_t$,先做低秩投射得到 indexer query:
\(\mathbf{c}_t^Q = \mathbf{h}_t \cdot W^{DQ}\) \(\mathbf{q}_t^l = \mathbf{c}_t^Q \cdot W^{IUQ}\)
同时计算动态 head routing weights:
\[\mathbf{w}_t^l = \mathbf{h}_t \cdot W^w\]最终的 lookahead index score:
\[I_{t,s} = \sigma\left(\sum_{h=1}^{n_h^l} \mathbf{w}_{t,h}^l \cdot \text{ReLU}\left(\mathbf{q}_{t,h}^l \cdot (K_s^{IComp})^T\right)\right)\]满足 $I_{t,s} \geq 0.5$ 的 entry $s$ 被加载到 GPU。
3.2 两层选择机制
FlashMemory 实际上是一个两级筛选:
- 第一级(Memory Indexer):粗粒度,每 64 步一次,从全量历史中选出”可能需要”的 chunk 集合 $C_t^{MemComp}$,从 CPU 加载到 GPU
- 第二级(原生 Lightning Indexer):细粒度,每步都做,在 $C_t^{MemComp}$ 这个缩小的范围内做正常的 ReLU Top-$k$ 选择,得到最终参与 attention 的 $C_i^{CoreComp}$
这种分层设计保证了:即使 Memory Indexer 的 recall 不完美,只要关键 chunk 被”宽松地”装进 GPU,原生的精确选择机制仍然能正常工作。
4. 训练:一张 H20 卡训一小时
这是这篇工作最让我印象深刻的地方。
Memory Indexer 的训练和整个 backbone 完全解耦。具体来说:
关键洞察:历史 entry 的 compressed indexer key $K_s^{IComp}$ 是在 backbone forward 时预计算好的、完全固定的。训练 Memory Indexer 本质上只是在训练一个 dual-encoder 的 query encoder——把当前 hidden state 映射到一个能正确匹配固定 key 的空间。
训练 pipeline:
- 离线跑一遍 DeepSeek-V4-Flash backbone,收集每个 token 的 hidden state 和 indexer key
- 构造 golden label(哪些 entry 是”真正需要的”)
- 只训练 query 端的低秩投影矩阵($W^{DQ}$, $W^{IUQ}$, $W^w$),用 Focal Loss
训练过程中 完全不加载 backbone 模型。参数量不到整个模型的 0.1%。
结果:在一张 H20 上跑 1 小时就收敛了。 8 张 H20 一周跑了 500 次实验扫参数空间。
这比传统的 end-to-end self-distillation(原生 Lightning Indexer 的训练方式)快了不知道多少个量级。
4.1 Golden Label 怎么造
直接用原生 Lightning Indexer 的 Top-$k$ 选择结果作为 label 会有严重的 inflation 问题——Top-$k$ 是固定数量的,不管这个 entry 有多不相关都会被选上。
FlashMemory 提出了 Cross-Layer Majority Voting 去噪:
- 对未来 window $[t, t+\tau-1]$ 内的每个 token $i$,收集 21 层 CSA 的原始 indexer logit
- 对每层做 Softmax + Top-$p$($p=0.6$)动态截断(而非固定 Top-$k$)
- 跨层投票:只有在 $\geq 3$ 层中都被独立选中的 entry 才认为是”golden”
- 对整个 window 取 union 作为最终正样本集合
这个 pipeline 把原始的约 10,000 个 pseudo-positive 过滤到 100-1,000 个 high-confidence entry。
4.2 最优配置:3 层就够了
并不是每一层 transformer 都适合做 lookahead prediction。浅层的表示主要是 low-level token statistics,做长程预测效果差。
通过 500 次 Pareto 优化,最终确定在 第 10、12、20 层 放置独立的 Memory Indexer,用 OR-mode 路由(三层中任何一层预测 $\geq 0.5$,就加载该 chunk)。
用 8 层?recall 太宽松,会把 30-49% 的历史 chunk 加载回来,失去了省显存的意义。用 1 层?代表能力不够。3 层是 sweet spot。
5. 实验结果
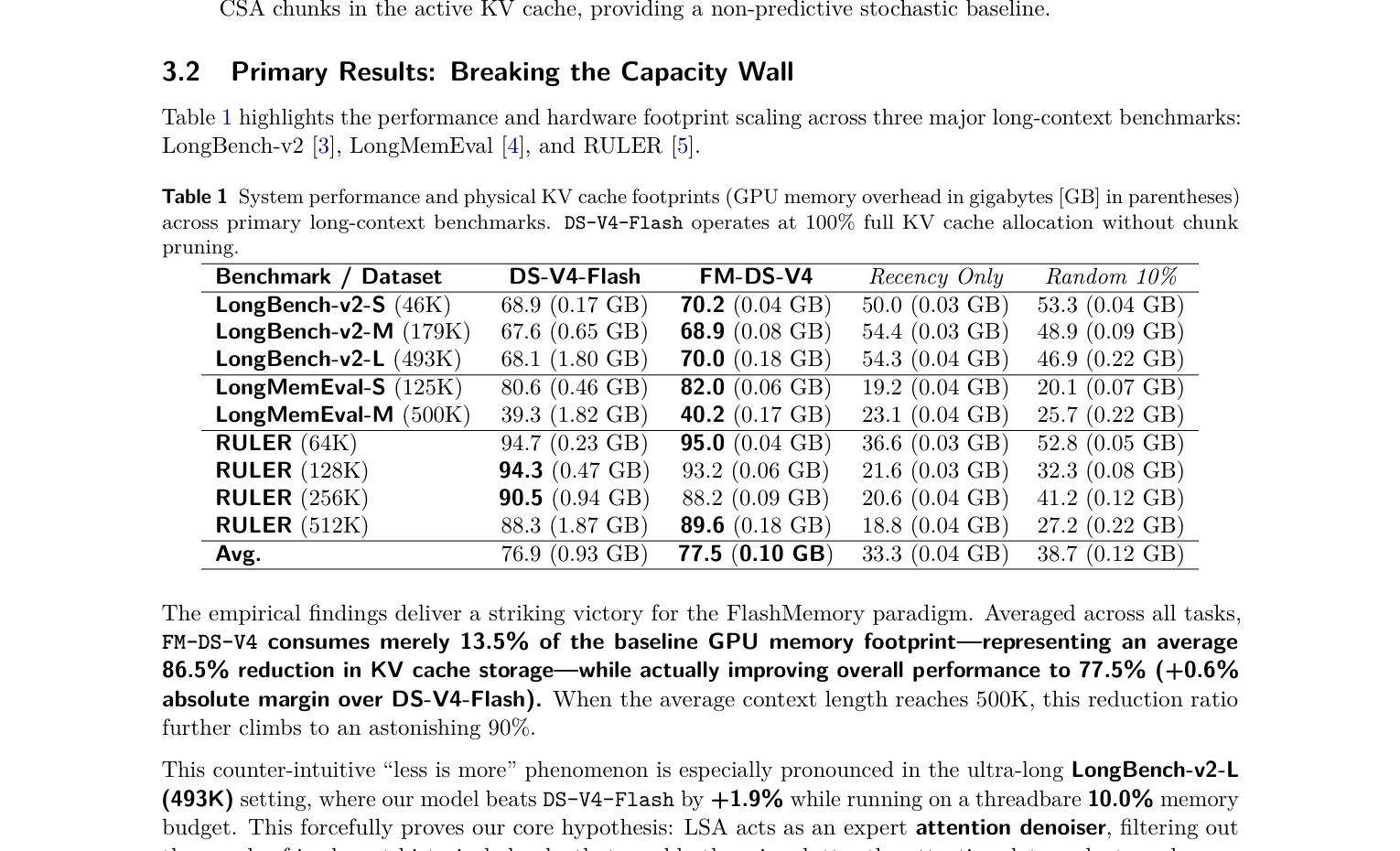
在三个主要长上下文 benchmark 上(LongBench-v2、LongMemEval、RULER):
| 指标 | DS-V4-Flash | FM-DS-V4 | Recency Only | Random 10% |
|---|---|---|---|---|
| 平均准确率 | 76.9% | 77.5% (+0.6) | 33.3% | 38.7% |
| 平均显存 | 0.93 GB (100%) | 0.10 GB (13.5%) | 0.04 GB | 0.12 GB |
几个关键数字:
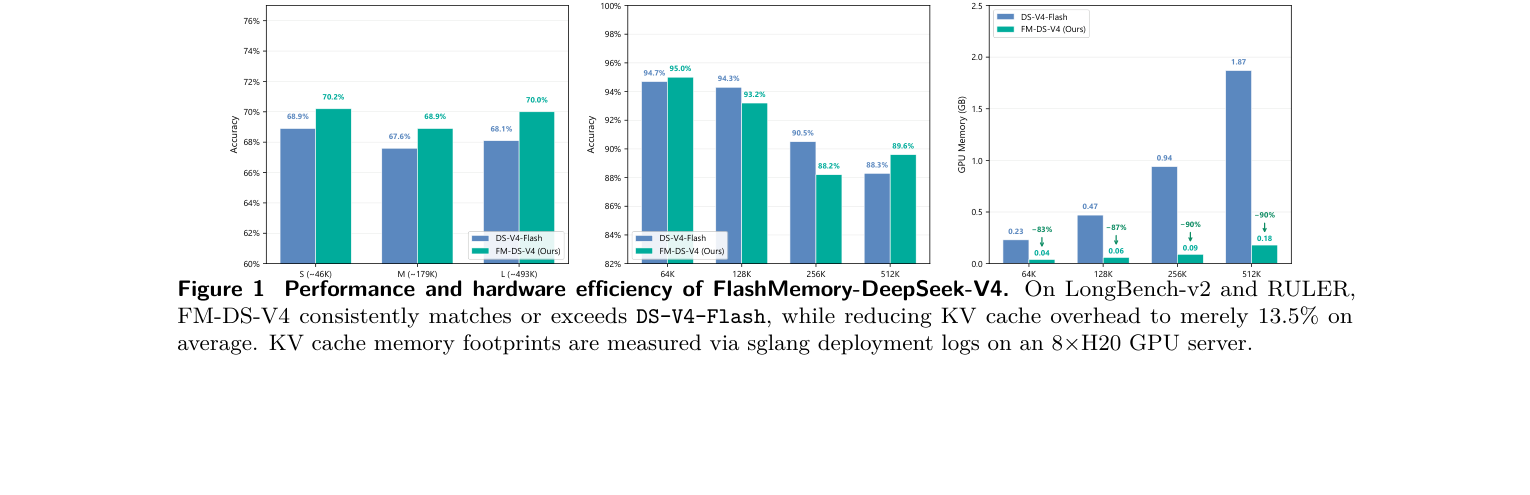
- LongBench-v2-L(493K context):FM-DS-V4 在只用 10% 显存的情况下比 baseline 高了 1.9 分。Less is more 在这里被最极端地验证——去掉噪声 chunk 反而减少了 attention 中的干扰
- RULER 512K:89.6 vs 88.3,FM-DS-V4 用 0.18GB vs baseline 的 1.87GB,显存压缩超过 90%
- Recency Only 和 Random 10% 全面崩溃(准确率只有 baseline 的一半不到),说明 Memory Indexer 确实学到了有意义的 temporal routing,不是随机碰运气
如下图是性能和显存的直观对比:
6. 局限性:不是万能的
这篇工作非常坦诚地列出了三个 failure case,我觉得这比单纯报正面结果有价值得多。
6.1 Context-Independent Overhead
理想状态下,如果当前 query 和历史 context 完全无关,Sigmoid gating 应该输出接近零的分数,不加载任何 chunk。但实际上 Sigmoid 存在”背景泄漏”——在 500K context 下,模型还是会误加载约 8.4% 的历史 chunk(虽然准确率没受影响)。
6.2 MRCR 崩溃(Dense Global Memory 任务)
在 Multi-Range Context Retrieval(MRCR)benchmark 上,准确率从 baseline 的 76.0% 暴跌到 48.0%。
原因:MRCR 要求模型同时精确回忆分散在全文多个位置的信息——这是一个”dense global memory”任务。即便给 oracle 50% 的 golden chunk,准确率也会下降 2%。这说明某些任务天生就不适合 sparse 策略,它们需要”全量密集记忆”。
Memory Indexer 基于浅层 dot-product 相似度做决策,缺乏 Late-Interaction(如 ColBERT 式 token 级交互),面对这类复杂的多点检索任务,能力有限。
6.3 长度泛化天花板
Memory Indexer 只能安全泛化到训练长度的 2 倍。超过这个边界,lookahead 选择退化为接近随机。作者把最终模型训练到 512K,推测超过 1M 就会失效。
本质原因是 positional embedding 的 out-of-distribution——这不是一般的检索模型,它依赖位置信息来建模”远处 vs 近处”的优先级。
7. 我的看法
先说我觉得好的部分。
“Backbone-free decoupled training”是这篇工作最值得学习的工程范式。 把一个复杂系统的优化分解为:固定 key representation + 只训 query encoder,这样一来训练成本从”需要加载整个千亿参数模型”变成”单张 H20 一小时”。这个思路对很多 retrieval-augmented 的系统设计都有启发意义。
Less is more 的实验结果很有意思。 FM-DS-V4 在 LongBench-v2-L 上不仅没掉点还涨了 1.9%,说明原生 full attention 确实存在”注意力噪声”问题——太多不相关的 chunk 参与 attention dot-product 会干扰模型决策。这个发现和 sparse attention 文献中的 “attention denoising” 观察一致。
但项目被暂停是遗憾的。 论文明确说了因为组织调整(project lead 离开腾讯),项目已经 suspended。很多关键 ablation 没做完——$\tau=64$ 和阈值 0.5 都是初步探索的值,没有系统对比。MRCR 上的 failure 也没来得及修(作者提出了 Late-Interaction 方向但未验证)。
从实际 serving 角度看,FlashMemory 的价值在于:如果你的业务以”长 context 但大部分回答不需要精确全文回忆”为主(这是绝大多数 RAG/agent 场景),那么它能用极低的显存服务超长 context。但如果你的场景是”必须精确检索全文多个位置的信息”(MRCR 类任务),目前的 Memory Indexer 还不够。
代码和模型都已开源:GitHub / HuggingFace。值得拉下来看看 Memory Indexer 的实现细节。
欢迎评论区交流,或者指出理解有偏差的地方。