arXiv'26 | Frontier:LLM 推理仿真器,端到端误差从 51.7% 降到 2.6%
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

arXiv’26 | Frontier:LLM 推理仿真器,端到端误差从 51.7% 降到 2.6%
原文:Frontier: Towards Comprehensive and Accurate LLM Inference Simulation
1. 前言
你有没有想过,在决定用 PDD 还是 co-location 部署一个 200B 的 MoE 模型之前,能不能先”模拟跑一遍”?
不是假设,是真实的问题。一个 200B 参数的 MoE 模型,合理的配置组合(parallelism 策略 + 批大小 + 架构选型)轻松超过 1000 种。在 64-GPU H100 集群上,扫 100 个配置就要花 12,800–25,600 GPU-hours,成本高达 $180,000。没有哪个团队能负担得起这个开销,大多数人的选择是”用个保守的默认配置凑合”,结果是白白损失了 3–5× 的吞吐量。
所以 inference simulator 这个方向一直有人做。但做好很难。
这篇来自香港中文大学 + StepFun 的工作——Frontier——正面硬刚了这个问题,给出了目前来看最系统的答案:端到端误差从对比方法的 51.7% 压到了 2.6%,还能模拟 1K+ GPU 的集群,跑在普通 CPU 上。
2. 现有仿真器差在哪?
先交代下背景:现有做 LLM inference simulation 的代表工作有四个——Vidur(微软)、AIConfigurator(NVIDIA)、LLMServingSim 2.0、APEX。
他们的问题集中在两点。
问题一:架构不完整。
现有仿真器大多是围绕”一组同质化的单体 replica”来建模的——每个 replica 跑完整的模型路径,调度状态自包含,本地循环执行。这套抽象对传统 co-location serving 够用,但在 disaggregated serving(PDD/AFD)面前就崩了。
PDD(Prefill-Decode Disaggregation)把 prefill 和 decode 拆到两组 GPU 上,KV cache 要跨集群传;AFD(Attention-FFN Disaggregation)进一步把 decode 阶段的 attention 和 FFN 分到不同硬件池。这种架构下,事件图本身就变了——请求要穿越多个 role-specific cluster,KV cache 传输是显式的因果边,MoE EP 引入了 routing 依赖的同步。
你没法”加一个 latency term”来给单体仿真器打补丁,这是架构层面的不匹配。
问题二:仿真精度不够,会让你选错配置。
更离谱的是,现有仿真器的精度差到可以让你做出错误决策。
如下图,现有方法对 CUDA Graph 的建模是缺失的。CUDA Graph 会把 decode 的 TPOT 降低 32%–47%(co-location)或 37%–60%(PDD),但同时会因为 batch size 对齐产生 padding overhead,增加 22%–58% 的无效 token 计算。这两个效果耦合在一起,任何标量 speedup factor 都无法同时捕捉,但 AIConfigurator 直接忽略了 CUDA Graph 建模。
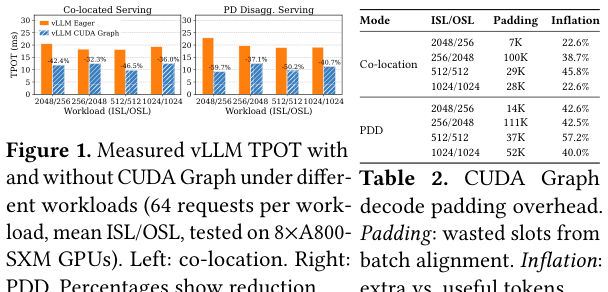
更严重的是保真度问题。以算子为例:Vidur 用 token count 作为 FlashAttention 的 runtime 预测特征,误差 p50/p95 达到 55.4%/376.1%。对于 MoE 的 GroupedGEMM,Vidur 直接没有建模。内存建模同样差:用”总显存减去模型权重”估算 KV cache budget 的方法(analytical 法),会高估 8.1%–27.2% 的可用 KV cache,进而虚报 23.6%–32.4% 的解码吞吐量。下图直接展示了这两个问题的量化结果:
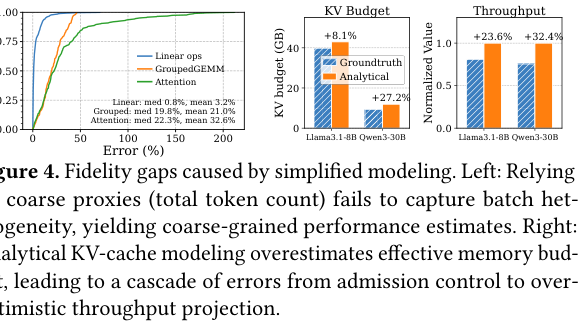
这两个误差不是独立的——KV cache 算多了,调度器能接的请求多了,实际 GPU 却装不下,于是发生 preemption,delay 被放大,TPOT 实测比仿真高出一大截。下图是最终结果:
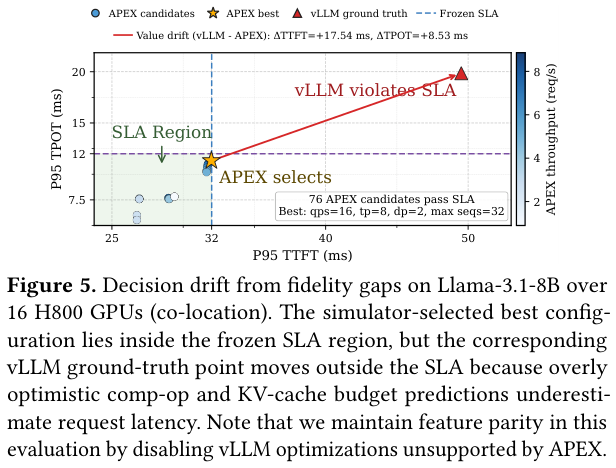
仿真器(APEX)选出了一个”最优配置”,但因为算子 runtime 和 KV cache budget 预测过于乐观,这个配置在实际 vLLM 上运行时超出了 SLA 边界。仿真本来是为了帮你避免踩坑,结果踩坑踩得更准。
这就是 Frontier 要解决的问题。
3. Frontier 怎么做的
Frontier 的整体架构分四个模块:
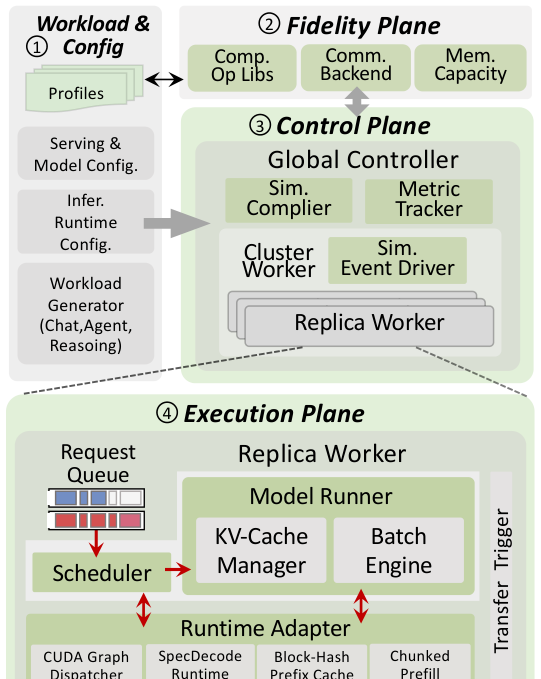
① Workload & Config:描述仿真场景(模型、serving 架构、parallelism、workload 类型);② Fidelity Plane:提供经过校准的算子 runtime、通信开销、KV cache budget 预测;③ Control Plane:把 serving 配置编译成可运行的仿真拓扑,处理 disaggregated 架构的跨集群依赖;④ Execution Plane:驱动每个 replica 内部的调度-批处理-执行循环,支持 runtime adapter 注入各种优化特性。
核心设计有三点,分别对应两个根本问题。
3.1 Control Plane:disaggregated 抽象
这是解决”架构不完整”的关键。Frontier 放弃了单体 replica 抽象,引入 role-specific cluster worker 的概念。每种 serving 架构对应不同的 role 集合:
- Co-location:单一集群 C,同时处理 prefill 和 decode
- PDD:prefill 集群 P + decode 集群 D,二者通过 KV cache 传输同步
- AFD:prefill 集群 P + attention 集群 A + FFN 集群 F,decode 阶段 A→F→A 每层激活传一次
跨集群的依赖(KV cache transfer、activation transfer、MoE EP 同步)都作为显式事件建模到 DES 事件图里。每次 prefill 完成,触发 KVCacheTransferStart 事件,decode cluster 在 Transfer End 后才能接管请求——排队延迟和同步都从事件图里自然涌现,不是靠”加个 latency 系数”糊的。
对于 reasoning/agent/RL rollout 这类有状态的 workload,Frontier 引入了 stateful request 抽象:每个请求可以携带思考轮数、每轮的 tool call 延迟、每轮的 prefill/decode token 计划,在推理结束前持续在集群内重入调度。
3.2 Execution Plane:Runtime Adapter 机制
为了把 CUDA Graph、speculative decoding、prefix caching 这些优化建进来,Frontier 设计了 Runtime Adapter 抽象——每个 adapter 只改调度循环中一个明确划定的切片:
- CUDA Graph adapter:decode batch 按 capture bins({1,2,4,8,16,32,64})向上对齐,把 padding 后的 batch 大小报给 Fidelity Plane,同时切换到 kernel-only(无 launch overhead)的计时模式。padding 引入的额外 token、graph 去掉的 launch overhead,两个效果同时被捕捉到。
- Speculative decoding adapter:per-request 维护 planned/verified/accepted/committed token count,MTP 的 draft→verify→commit 循环跟普通 decode work 共享 batch,不同请求可以有不同的 speculative depth 和不同的 acceptance outcome——tail latency 的来源在这里。
这种 adapter 机制的好处是:优化特性不需要硬编码进 simulation core,可以独立开发、独立测试。
3.3 Fidelity Plane:三类算子,精准建模
现有方法用 token count 作为所有算子的 proxy feature,这是保真度差的根本原因。Frontier 把算子分成三类,分别用不同的预测策略:
- Token-count operators(GEMM、elementwise、norm):runtime 主要取决于 TP slice 里的 token 数,线性回归或小 random forest 就够了。
- Sequence-dependent operators(attention):runtime 和 batch 内各请求的序列长度分布强相关,不只是总 token 数。Frontier 用 random forest,feature 包含 batch size、total tokens、prefill/decode 长度的 min/max/分位数。这就能捕捉到 chunked prefill 下的非线性行为。
- Routing-dependent operators(MoE GroupedGEMM):runtime 和 token-to-expert 路由分布有关。feature 加入了 load balance 统计(variance、max of expert token counts)、expert selection ratio 等。
内存建模方面,Frontier 做了一次 dummy profile run(用假权重初始化模型,跑一次 forward,读 PyTorch allocator snapshot),得到三个分量:权重内存、torch peak 增量(activation scratch)、non-torch residency(NCCL workspace 等)。KV cache budget = 总显存预算 - 权重 - profiled non-KV overhead。这比”总显存减权重”精准得多。
4. 实验结果
4.0 论文怎么证明 Frontier 可信?
在看具体数字之前,先说清楚这篇论文的验证思路——这是判断”结论能不能信”的关键。
Frontier 的验证分三层,从底层到顶层依次累积:
第一层:算子级 microbenchmark。 在真实 H800 GPU(BF16 + FP8)上,profiling 各类算子(GEMM、attention、GroupedGEMM、all-reduce)在不同 batch size、序列长度、并行配置下的实际 runtime,和 Frontier 的预测值对比。这一层的目的是隔离其他因素,单独验证 Fidelity Plane 的建模是否准确。
第二层:组件级验证。 单独测试各 runtime adapter 是否正确建模了对应的优化效果——CUDA Graph adapter 在不同 workload 下对 TPOT 的缩减比例是否和 vLLM 实测一致,prefix cache 的 block 命中率曲线是否跟踪准确,KV cache budget 和 profiling 实测值的偏差是多少。
第三层:端到端 testbed 对比。 这是最关键的一层。用 16 张 H800 搭真实 vLLM 集群,跑真实请求流,把 vLLM 的 TTFT/TPOT/throughput/E2E makespan 作为 ground truth,和 Frontier 仿真结果逐点对比。覆盖两种模型(dense + MoE)× 两种架构(co-location + PDD)× 四种 workload 模式,共 64 个 case。
这个设计的合理之处在于:如果第一层准,第三层就应该准;如果第三层有系统性偏差,能回溯到第一层定位原因。这比”只报端到端误差”更有说服力,因为每一层的误差来源是可以分开解释的。
4.1 算子和内存精度
先看算子级精度。在 H800 BF16 下,Frontier 的 attention p50/p95 误差是 3.5%/14.2%,Vidur 同样数据下是 55.4%/376.1%。FP8 下 Frontier p95 进一步降到 8.8%,而 Vidur 根本不支持 FP8。
KV cache budget 方面,Frontier 在所有 4 种并行配置下把初始 block 数量的误差控制在 1.89% 以内;analytical 方法(”总减权重”)高估 14.10%–39.73%。
4.2 端到端仿真精度
这是最关键的数字:
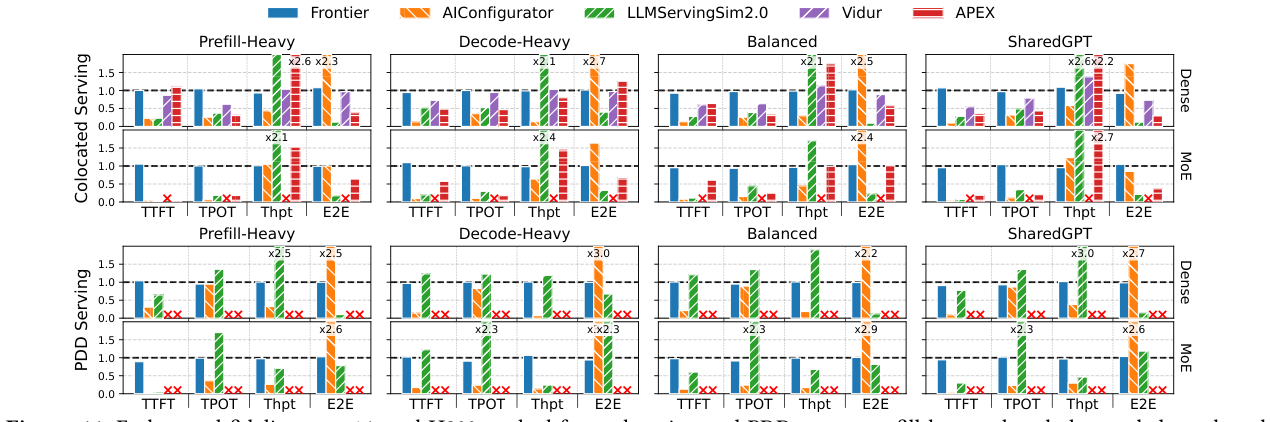
在 16 卡 H800 testbed 上,跨 dense(Llama3.1-8B)和 MoE(Qwen3-30B MoE)、co-location 和 PDD、四种 workload pattern(prefill-heavy、decode-heavy、balanced、SharedGPT):
- Co-location:Frontier 在 32 个 case 里跟 vLLM 误差 < 9.37%;Vidur 最差到 45.5%;AIConfigurator 在 decode-heavy 下 E2E makespan 误差飙到 170.0%。
- PDD:Frontier 32 个 case 全部在 10.99% 以内,29 个在 9% 以内;AIConfigurator 在 dense 和 MoE 的 decode-heavy 下 E2E 误差都达到 200%(architecture level 的崩塌,没有 KV cache transfer dependency 建模,任何 scalar 修正都救不了);Vidur 和 APEX 直接不支持 PDD。
- AFD:在 Step3-316B 上,Frontier 把 TPOT 控制在 6.4% 以内、throughput 在 7.0% 以内。没有其他仿真器能跑 AFD。
和 SOTA 对比(AIConfigurator):SharedGPT trace 下,E2E latency 误差从 44.9% → 6.4%(co-location),51.7% → 2.6%(disaggregation)。
5. 用来干什么
这才是这篇工作真正有意思的地方——四个 use case,没有一个是之前的仿真器能复现的。
5.1 Pareto frontier 探索
256 卡 H800,部署 Llama-3.3-70B,对比 co-location/PDD/AFD。合理的配置空间有 483,536 种,扣掉 OOM 的还剩 496 个满足 SLA 的。
Frontier 扫完之后给出了三条 Pareto 曲线:
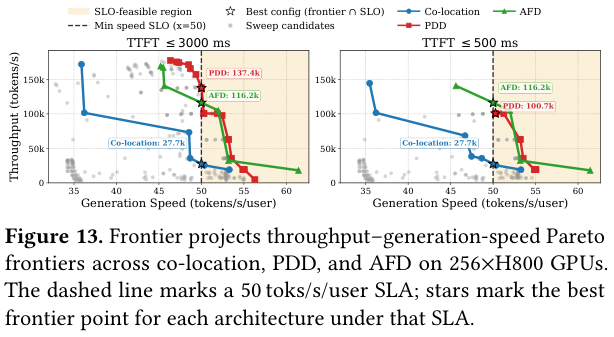
结论:SLA 松(TTFT ≤ 3000ms)时,PDD 最优(137.4K toks/s);SLA 紧(TTFT ≤ 500ms)时,AFD 反而更好(116.2K toks/s,PDD 在这个约束下只能做到 100.7K)。
如果没有仿真器,就只能在”松 SLA 下 PDD 看起来更好”这个错误结论上停下来。
5.2 异构 GPU 分配
1024 卡集群(H800 + H20 混用,H800 $3.49/h,H20 $1.59/h),部署 Qwen3-235B-A22B。结论很实际:
- 便宜不代表合适:把 H20 放在 compute-bound 的 FFN role 上,性价比不升反降(CE < 1.08,被 Gate 1 过滤掉了);
- 对的 role 才能省钱:PDD 下把 D role 换成 H20(P:D=1:1),省了 37% 的成本,性价比提升 33%,SLA 也守住了;AFD 下把 attention cluster 换成 H20,省 16%,CE 提升 12%。
5.3 RL Rollout 动态 parallelism 切换
4000 条 trajectory 的 burst,5% 是 heavy tail。
- Layout A(DP=32,PP=16,TP=2):高 DP,适合 burst;
- Layout B(DP=8,PP=16,TP=8):宽 TP,适合 tail 阶段 per-trajectory decode;
- 动态策略:burst 阶段用 A,active trajectory < 10% 时切换到 B。
结果:makespan 从 528.8s → 259.1s,decode throughput 提升 2.04×。
6. 一些想法
先说我认为这篇工作好的地方。
最本质的贡献是把”disaggregated serving 仿真”这件事做到了工程层面可用。PDD 在工业界(DistServe、Mooncake)已经是标配,AFD 也在 MegaScale-Infer 里被验证过,但现有仿真器在这块全是空白。Frontier 填的这个空,不是”做了个能跑的 prototype”,而是误差在 10% 以内的 decision-grade 仿真。
三类算子的分类(token-count / sequence-dependent / routing-dependent)也挺扎实,是从真实的 kernel 行为出发做的归纳,不是拍脑袋分的。CUDA Graph 的双效果建模(padding + launch overhead 各自独立捕捉)这个细节我觉得做得对,这个坑确实不好踩。
然后谈谈我对”这个仿真器到底可不可信”这个问题的看法——毕竟验证方法设计得再合理,也有它覆盖不到的地方。
大规模准确性没有 ground truth。 论文端到端验证用的是 16 卡 H800。但 use case 部分拿去用的是 256 卡(Pareto 探索)和 1024 卡(异构 GPU 分配)。两者之间差了 16–64×,这中间的 gap 完全没有实测验证。论文的隐含假设是算子级和端到端误差在更大规模下保持稳定,但大规模下集合通信的 congestion 模式、跨集群的 scheduling 交互、rack-level 的 incast 效应——这些在 16 卡上几乎观察不到,却可能在真实的 1K GPU 集群上出现。文中对此没有任何量化分析。
校准数据对硬件和框架版本敏感。 Frontier 的算子预测模型是用 H800 BF16/FP8 profiling 数据训练的。换到 H100、A100、或者 AMD MI300x——calibration 数据直接作废,需要重新采集。更新 vLLM 版本同理:v0.10.2 之后 vLLM 持续迭代调度逻辑,CUDA Graph 的 capture bins 也可能改动。论文没有说清楚 recalibration 的成本和频率,这对长期使用是个实际问题。
MoE GroupedGEMM 的 p95 误差仍然非平凡。 Frontier 的 GroupedGEMM 预测 p50/p95 是 4.4%/17.2%。对于 GroupedGEMM 占主导的大规模 MoE(比如 Qwen3-235B-A22B),p95 17% 的单算子误差叠加多层之后对尾延迟的影响有多大?论文没有单独分析这个误差传播链。
workload 分布是个盲点。 实验用的四种 workload 模式都是事先固定分布的。但生产流量是非平稳的:早高峰和夜间流量特征不同,用户行为随应用演进变化。Frontier 能处理给定 trace 的仿真,但对分布 shift 有多鲁棒——完全没有讨论。
综合来看,Frontier 的验证在现有仿真器里是最扎实的,三层验证结构(算子→组件→端到端)也是正确的思路。但”16 卡 → 1K 卡”这个尺度 gap 是我目前最不放心的地方。如果有机会在更大规模的 testbed 上做一次 validation,说服力会强得多。
对于做 LLM serving 研究、需要快速探索部署配置空间的团队来说,这工具是有用的:在 CPU 上跑仿真,误差 < 10%,不用花 $180,000 扫集群。代码还没有开源(截稿时),等出来值得拉下来配合真实 profiling 数据用用。
如果有用,欢迎评论区交流,或者指出理解有偏差的地方。