arXiv'26 | ELF:Flow Matching 生成文字,用 10 倍少的数据全面超越主流 Diffusion LM
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

arXiv’26 | ELF:Flow Matching 生成文字,用 10 倍少的数据全面超越主流 Diffusion LM
原文:ELF: Embedded Language Flows
作者:Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, Kaiming He(MIT)
代码:https://github.com/lillian039/ELF
1. 前言
你有没有想过,为什么用 Diffusion model 生成图片这么自然,用来生成文字却这么别扭?
Stable Diffusion、FLUX 满大街都是,图像生成效果惊艳。但 Diffusion 语言模型(DLM)一直活在 GPT/LLaMA 这类自回归模型的阴影下——又慢,效果又差,inference 还要跑几百步。这其中有什么根本原因?
MIT 这篇 ELF(Embedded Language Flows,Kaiming He 是 co-author)给了一个很干净的答案:连续 Diffusion LM 打不过离散方案,不是因为”文字本身是离散的”这个本质问题,而是之前大家的算法设计选错了。 换一套做法,用 10 倍少的训练 token,步数更少,就能超越 MDLM、Duo 这类离散 DLM。
今天想和大家聊聊 ELF 到底解决了什么真问题。因为涉及 Diffusion 和 Flow Matching 的基础,我会先从头讲清楚这些概念——不是泛泛地说”加噪去噪”,而是把它讲到你能看懂 ELF 的设计为止。
2. Diffusion 和 Flow Matching 到底在干什么?
2.1 核心目标:学会从噪声里还原数据
不管是 DDPM 还是 Flow Matching,目标都是同一件事:
训练一个网络,输入”被噪声污染的数据”,输出”去掉噪声后的干净数据”。
一旦这个网络训好了,生成时就从一团纯随机噪声出发,反复调用网络去噪,最终得到一个逼真的生成结果(图片或文字)。
区别在于”怎么加噪、怎么去噪”——DDPM 的路径弯,需要 1000 步;Flow Matching 的路径直,32 步就够。为了说清楚这个差异,我们直接看 PyTorch 伪代码。
2.2 DDPM 训练:给数据掺噪声,学着把噪声去掉
# ===== DDPM 训练一步 =====
# x: 干净数据, shape [B, D]
# - 图像生成时: x = 一张图片的像素值 (如 [B, 3, 256, 256])
# - 文本生成时: x = 一段话的 embedding 向量 (如 [B, seq_len, 512])
noise = torch.randn_like(x) # 随机高斯噪声,和 x 同形状
t = torch.randint(0, T, (B,)) # 随机选一个时间步 t ∈ {0,...,999}
alpha_bar_t = alpha_bar_schedule[t] # 查表得到"此刻噪声占比"
# 加噪:把干净数据和噪声按比例混合
z_t = sqrt(alpha_bar_t) * x + sqrt(1 - alpha_bar_t) * noise
# 网络预测:输入被污染的 z_t 和时间步 t,试图还原出加入的噪声
noise_pred = model(z_t, t) # 输出和 noise 同形状
loss = MSE(noise_pred, noise) # loss = 预测噪声 vs 真实噪声
loss.backward()
直觉:$t$ 越大,alpha_bar_t 越小,z_t 里噪声占比越高,网络任务越难。$t=0$ 时 z_t ≈ x(几乎没加噪),$t=999$ 时 z_t ≈ noise(看不出原始数据了)。
DDPM 推理(从噪声反推数据):
# ===== DDPM 推理(生成) =====
z = torch.randn(B, D) # 从纯噪声出发(对应 t=T)
for t in reversed(range(T)): # 从 t=999 倒退到 t=0
noise_pred = model(z, t) # 网络预测 z 里混了多少噪声
# 用预测的噪声"减掉"一部分,让 z 稍微变干净一点
z = (z - beta[t]/sqrt(1-alpha_bar[t]) * noise_pred) / sqrt(1-beta[t])
if t > 0:
z += sqrt(beta[t]) * torch.randn_like(z) # 加一点随机扰动(SDE)
# 循环结束后 z ≈ x(干净数据)
注意这里每步要做除法、查表、加随机噪声——公式复杂,而且必须走满 1000 步(或用 DDIM 加速到 50~200 步)。
DDPM 的根本问题:alpha_bar_t 的衰减曲线不是均匀的(它是一堆 $1-\beta_t$ 的连乘积),导致 $\boldsymbol{z}_t$ 从 $\boldsymbol{x}$ 到噪声的路径弯弯曲曲。推理时必须沿着同样弯的路径一小步一小步回退,需要 200~1000 步,非常慢。
2.3 Flow Matching 训练:一行代码搞定加噪
Flow Matching 的关键改进就一句话:把弯曲路径换成直线。怎么做?加噪公式不用复杂的 alpha_bar 调度表,直接用最简单的线性插值:
# ===== Flow Matching 训练一步 =====
noise = torch.randn_like(x)
t = torch.rand(B) # t ∈ [0, 1] 连续均匀采样
# 加噪:直接线性插值!
z_t = t * x + (1 - t) * noise # t=0 时纯噪声,t=1 时干净数据
# 网络预测干净数据 x(x-prediction)
x_pred = model(z_t, t)
loss = MSE(x_pred, x)
loss.backward()
就这么简单。对比一下 DDPM:没有 alpha_bar_schedule,没有开根号,没有查表——加噪就是一次线性插值。
但是,为什么网络能从 z_t 里还原出 x?
初看这个训练代码可能觉得奇怪:z_t 是 x 和 noise 的混合物,而 noise 是随机的——网络怎么能从这堆混合里把 x 猜出来?
关键在于 t 告诉了网络”信号占多少比例”。举一个具体例子:
-
t = 0.9:z_t = 0.9 * x + 0.1 * noise。此时z_t里 90% 是干净数据、10% 是噪声。网络看到的几乎就是原图稍微加了点毛刺,还原x很容易——就像看一张轻微模糊的照片,你一眼就能认出内容。 -
t = 0.5:z_t = 0.5 * x + 0.5 * noise。一半信号一半噪声,像隔着毛玻璃看。网络还能猜到大致轮廓,但细节得靠”经验”(从训练数据里学到的统计规律)。 -
t = 0.1:z_t = 0.1 * x + 0.9 * noise。几乎全是噪声,只有 10% 的微弱信号。网络基本靠”想象”——根据那一丝微弱线索和它学到的数据分布来猜。
本质上,这就是一个”不同难度的去噪任务”:
- 噪声少时($t$ 大)→ 容易的去噪,网络学精修细节
- 噪声多时($t$ 小)→ 困难的去噪,网络学整体结构和分布规律
同一个网络同时学所有难度级别,最终就掌握了”从任意噪声程度还原数据”的完整能力。这和 DDPM 的思路本质相同,只是混合比例的公式从弯曲的 sqrt(alpha_bar) 换成了简单的线性 t。
为什么这叫”直线”? 想象一个高维空间里有两个点:纯噪声 noise(起点)和干净数据 x(终点)。随着 $t$ 从 0 到 1,z_t = t*x + (1-t)*noise 在这两点之间匀速直线移动。画出来就是一条笔直的连线,不拐弯。DDPM 那个带 sqrt(alpha_bar) 的公式画出来则是一条弧线(因为 x 和 noise 前面的系数变化不均匀)。
2.4 Flow Matching 推理:为什么需要”速度”
训练时我们知道 x(干净数据就在手边),但推理时 x 是我们要生成的未知量——我们只有纯噪声 z_0 = noise,要一步步走到 x。问题来了:不知道终点在哪,怎么走?
答案是靠网络告诉你每一步往哪个方向走、走多远。这个”方向+步长”在数学上就叫速度。
来看推理代码就明白了:
# ===== Flow Matching 推理(生成) =====
z = torch.randn(B, D) # 从纯噪声出发
steps = 32
dt = 1.0 / steps # 每步走 1/32 的时间
for i in range(steps):
t = i * dt # 当前时间
x_pred = model(z, t) # 网络预测"终点在哪"
velocity = x_pred - z # "终点 - 当前位置" = 要走的方向和距离
# 注意:这里不是一步跳到 x_pred,而是只走一小段
z = z + dt * velocity # 往终点方向移动一小段
# 循环结束后 z ≈ x(干净数据)
为什么叫速度? 物理直觉:你站在 z(当前位置),想走到 x_pred(网络猜的终点),两者之差 x_pred - z 就是位移方向。除以时间就是速度,乘以 dt(一小段时间)就是这一步实际走的位移。跟初中物理的”路程 = 速度 × 时间”完全一样。
为什么不一步直接跳到 x_pred? 因为早期 $t$ 很小时,z 几乎是纯噪声,网络的预测 x_pred 不太准(噪声太大,信息太少)。所以只走一小步,到了新的 z 之后重新问网络,逐步修正。随着 $t$ 增大,z 越来越像干净数据,预测也越来越准,最后几步几乎可以一步到位。
为什么 Flow Matching 只要 32 步? 因为真实路径是直线。网络学的”速度”在路径上每个点都指向同一个方向(终点),所以哪怕步子大一点也不会偏离轨道太多。DDPM 的路径是弯的,步子大了就走偏,必须小步碎走。
2.5 网络也可以预测别的东西
上面的代码里网络预测的是 x(干净数据),这叫 x-prediction。其实网络也可以选择预测别的量:
- x-prediction:网络输出 $\hat{x}$,然后用
velocity = x_pred - z算速度。直觉:”直接猜终点在哪” - v-prediction:网络直接输出速度 $\hat{v}$,推理时直接用
z = z + dt * v_pred。直觉:”直接猜该往哪走” - ε-prediction:网络输出噪声 $\hat{\epsilon}$,用 $\hat{x} = (z_t - (1-t)\hat{\epsilon}) / t$ 反推 $x$。直觉:”猜这团东西里混了多少噪声”
三种方式在数学上等价(知道一个就能算出另外两个),但在实际训练中稳定性不同。ELF 只能用 x-prediction——原因在第 4 节详细讲。
3. 文字 ≠ 图像:Diffusion LM 的困境
3.1 根本矛盾:离散 vs 连续
Diffusion 模型设计上就是为连续数据服务的——图像的像素值是实数,加减高斯噪声天然合理。
文字是离散的,token 只是一个整数 ID。你无法直接在 token 上加高斯噪声——token 42 加上 0.3 的噪声还是 token 42,没有意义。
历史上大家走了两条路:
路线一:连续 DLM。 先把 token 映射到连续的 embedding 向量(比如用神经网络的 word embedding),再在这个连续空间里做 diffusion。生成结束后,再把连续 embedding 转回 token。代表工作:Diffusion-LM、DiffuSeq、CDCD。
路线二:离散 DLM。 发明一种直接作用在 token 上的”噪声”。最直观的做法是用 [MASK] 替换 token(类似完形填空),逐步 mask 越来越多,然后学会逆向逐步 unmask。代表工作:MDLM(masked diffusion)、Duo(uniform diffusion)。
离散 DLM 目前效果更好,是主流。 连续 DLM 被一直追赶但追不上。
3.2 连续 DLM 为什么一直输?
连续 DLM 的核心难题是接口问题:中间过程在连续 embedding 空间,最终输出必须是离散 token,这个桥怎么搭?
以往大家的解法普遍有两个问题:
问题一:每步去噪都往 token 对齐(per-step discretization)。 很多早期连续 DLM 在每个中间步都加一个 cross-entropy loss,强迫中间的 embedding 也对应到某个 token。结果是连续空间里的 trajectory 被 token 空间”拴住”了,丧失了在连续空间里自由流动的优势。
问题二:需要单独训练一个 decoder。 Latent Diffusion 类方法(如 LD4LG)把连续 diffusion 在 encoder 的 latent 空间里做完后,再训一个 decoder 把 latent 解码回 token。两个模型,训练更复杂,推理要多跑一次 decoder。
看下图(Table 2)可以更直观地感受——现有连续 DLM 在”Train per-step discr.”或”Sep. dec.”这两列几乎全部打了勾。而 ELF 是这张表里唯一一个两列都是空白的方法:
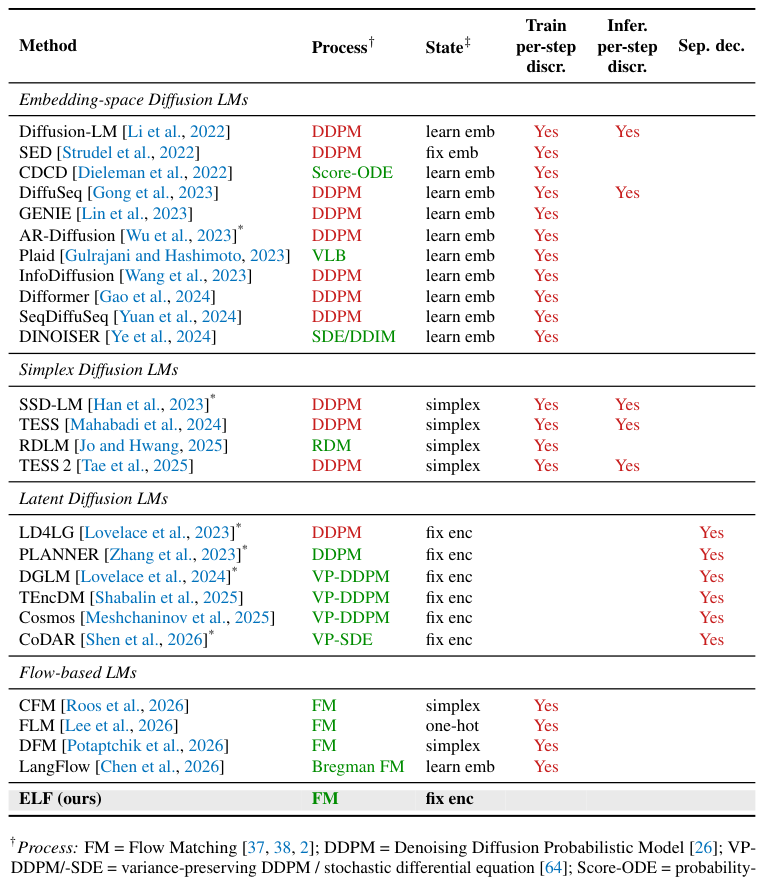
4. ELF:最后一步才 token
4.1 一句话概括
ELF 的方案极简:全程在连续 embedding 空间里跑 Flow Matching,只在最后一步($t=1$)把 embedding 解码成 token。
如下图(Figure 2)所示,橙色点是 embedding 空间里的数据,紫色线是去噪轨迹——从 $t=0$(纯高斯噪声)一路走到 $t=1$(干净 embedding),最后一步才 argmax 到 token:
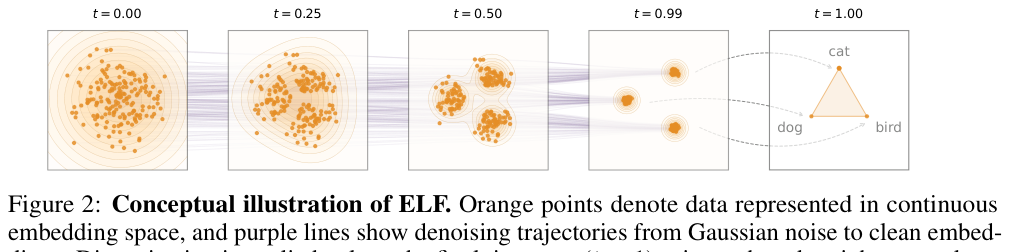
这个设计为什么合理?因为 Flow Matching 在 $t=1$ 时本来就是”干净数据”,只差最后一步把它投影到最近的 token。这个操作不是额外加的,而是 Flow Matching 框架里最后一步的自然意义。
4.2 完整框架
训练时(如下图 Figure 3 左半部分):
- 把输入 token 序列 $\boldsymbol{s}$ 用预训练 T5 encoder 编码成干净 embedding $\boldsymbol{x}$
- 按 Flow Matching 加噪:$\boldsymbol{z}_t = t\boldsymbol{x} + (1-t)\boldsymbol{\epsilon}$
- 网络 $\text{net}_\theta$ 预测干净 embedding $\hat{\boldsymbol{x}}$(x-prediction),用 MSE loss:
- 对于最后一步 $t=1$:同一个网络切换到 “decode” 模式,输出经过 unembedding 层 $W$ 得到 logit,CE loss:
推理时(Figure 3 右半部分):从 $\boldsymbol{z}_0 \sim \mathcal{N}(0, \boldsymbol{I})$ 出发,Euler 步迭代,最后一步 argmax 得到 token:
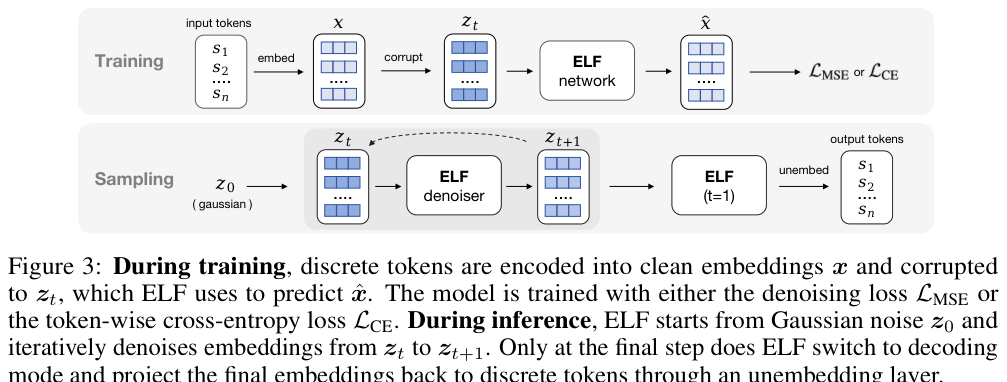
关键点:T5 encoder 只在训练时使用,用于提供高质量的 embedding 作为学习目标。推理时不需要 encoder,只需要网络本身跑 ODE。
4.3 共享权重 denoiser-decoder
前面说 denoiser 和 decoder 是”同一个网络”——这是 ELF 的精妙之处。网络通过一个二值 mode token 区分:
-
mode = "denoise":中间步去噪,MSE loss -
mode = "decode":最后步解码,CE loss
训练时 80% 的 batch 走 denoise 分支,20% 走 decode 分支,两部分的 loss 合并更新同一套权重。推理时只在 $t=1$ 切一次 decode,完全不需要额外的 decoder 网络。
消融实验显示:shared-weight 方案与单独训练 decoder 的效果相近,但在低 perplexity 区间能推得更远,且省了一个训练阶段。
4.3a 看源码:ELF 的训练和推理实际长什么样
以下是从 ELF 官方 PyTorch 代码 提炼的简化版核心逻辑,帮助理解输入输出的完整计算流。
训练一步(简化自 src/train_step.py + src/utils/sampling_utils.py):
# ===== ELF 训练一步(简化版) =====
# 输入: input_ids [B, seq_len] — 一个 batch 的 token 序列
# Step 1: Token → 连续 embedding(通过冻结的 T5 encoder)
x0 = t5_encoder(input_ids) # [B, seq_len, 512] 干净 embedding
# Step 2: 采样随机时间步 t(logit-normal 分布,让中等噪声水平被更多采样)
t = torch.sigmoid(torch.randn(B) * 0.8 - 0.8) # [B] ∈ (0, 1)
# Step 3: Flow Matching 加噪
noise = torch.randn_like(x0) # [B, seq_len, 512]
z_t = t[:, None, None] * x0 + (1 - t[:, None, None]) * noise # 线性插值
# Step 4: 每个样本随机决定走哪个分支(伯努利采样,80% denoiser / 20% decoder)
is_decoder = torch.bernoulli(torch.full((B,), 0.2)) # [B]
# Step 5: Decoder 分支的输入 — t=1 但故意加了 per-token 噪声(模拟推理时的不完美)
lambda_t = torch.sigmoid(torch.randn(B * seq_len) * 0.8 + 0.8) # per-token
decoder_z = lambda_t * x0 + (1 - lambda_t) * noise_decoder # 接近干净,但不完美
# Step 6: 拼混合输入(decoder 分支用 decoder_z,denoiser 分支用 z_t)
z_mixed = is_decoder * decoder_z + (1 - is_decoder) * z_t
t_mixed = is_decoder * 1.0 + (1 - is_decoder) * t
# Step 7: 网络前向(同一个网络,一次 forward 同时出两个 head 的结果)
x_pred, decoder_logits = model(z_mixed, t_mixed, decoder_step_active=is_decoder)
# x_pred: [B, seq_len, 512] — denoiser 分支的 x-prediction
# decoder_logits: [B, seq_len, vocab_size] — decoder 分支的 token 预测
# Step 8: 算速度,然后 L2 loss(仅 denoiser 分支有效)
v_pred = (x_pred - z_t) / (1 - t[:, None, None]) # 从 x-prediction 推导速度
v_target = (x0 - z_t) / (1 - t[:, None, None]) # ground truth 速度
l2_loss = ((v_pred - v_target) ** 2).mean(dim=-1) # [B, seq_len]
# Step 9: CE loss(仅 decoder 分支有效)
ce_loss = F.cross_entropy(decoder_logits, input_ids, reduction='none') # [B, seq_len]
# Step 10: 合并两个分支的 loss(用 mask 分开)
loss = (l2_loss * (1 - is_decoder) + ce_loss * is_decoder).mean()
loss.backward()
推理(生成)(简化自 src/utils/generation_utils.py):
# ===== ELF 推理(生成)=====
# 无需 T5 encoder,直接从噪声出发
# Step 1: 初始化纯噪声
z = torch.randn(B, seq_len, 512) # 纯高斯噪声
x_pred_prev = torch.zeros_like(z) # self-conditioning 初始为全零
# Step 2: 生成时间步序列 [0, t1, t2, ..., t_N-1, 1.0]
t_steps = torch.linspace(0, 1, steps=33) # 32 步 + 终点
# Step 3: ODE 循环 — 逐步从噪声走到干净 embedding
for i in range(32):
t, t_next = t_steps[i], t_steps[i + 1]
# 网络预测 x(self-conditioning: 把上一步的预测拼进输入)
z_input = torch.cat([z, x_pred_prev], dim=-1) # [B, seq_len, 1024]
x_pred = model(z_input, t) # [B, seq_len, 512]
# 从 x-prediction 推导速度
v_pred = (x_pred - z) / (1 - t)
# Euler 步:沿速度方向走一小段
z = z + (t_next - t) * v_pred
# 更新 self-conditioning 状态
x_pred_prev = x_pred
# Step 4: 最后一步 — 切换到 decode 模式,把连续 embedding 变成 token
_, decoder_logits = model(z, t=1.0, decoder_step_active=True)
tokens = decoder_logits.argmax(dim=-1) # [B, seq_len] 生成完毕!
几个值得注意的点:
- 训练时用 v_target 做 L2 loss(不是直接 MSE(x_pred, x0)),这是因为 $v = (x - z)/(1-t)$ 做了 $1/(1-t)$ 的加权,让 $t$ 接近 1 时 loss 被放大——逼迫网络在”快到终点”时预测更精确
- decoder 分支的输入不是纯净 x0,而是故意加了 logit-normal 噪声的 embedding,模拟推理时 ODE 最后一步输出的”不完美”结果
- self-conditioning:把上一步的 x_pred 拼接到当前输入里,让网络能”参考之前的猜测”来修正预测,不额外增加 forward pass 次数
4.4 为什么必须 x-prediction?
还记得前面说的三种预测目标?ELF 选 x-prediction,有两个不可绕过的理由:
理由一:高维空间的稳定性。 语言 embedding 的维度(T5-small 是 512 维/token,T5-large 是 1024 维/token)远比图像 patch 高。在这么高的维度里,干净的语言数据实际上分布在一个低维流形上——也就是说,512 维空间里大部分方向是”没有真实数据”的。
x-prediction 直接学习”怎么从噪声里恢复干净数据”,天然指向这个低维流形。而 v-prediction 学的是 $\boldsymbol{x} - \boldsymbol{\epsilon}$(干净数据减噪声),在高维里这个差值本身就很难学准,两个高维向量之差的误差会放大。ε-prediction 同理。
实验证实(下图 Figure 10):v-prediction 在 512 维还 OK,768 维以上就崩了(Gen. PPL 急剧升高);ε-prediction 在所有维度都崩;只有 x-prediction 全程稳定:
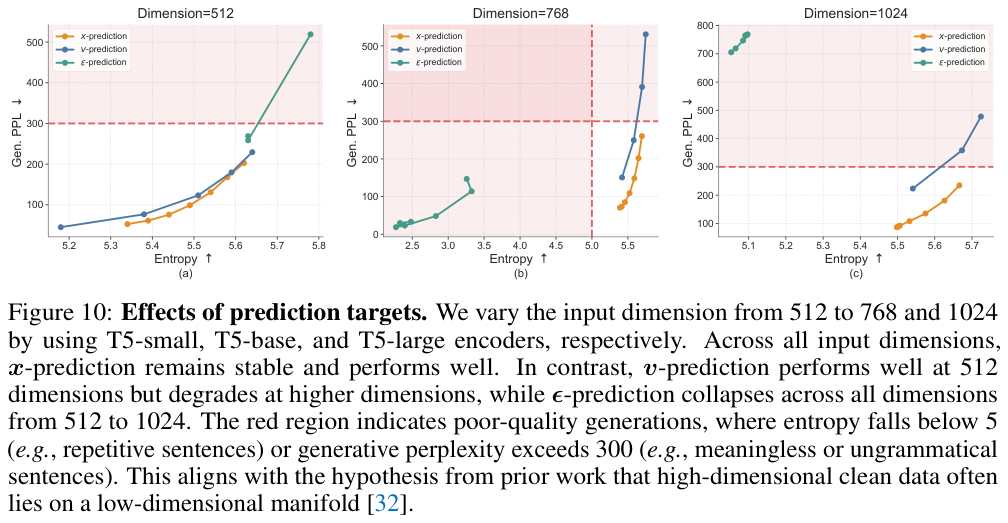
理由二:权重共享的内在要求。 Decoder 的任务是”给定(加了噪的)embedding,预测干净 token”,本质上是预测干净 embedding $\boldsymbol{x}$(然后通过 $W$ 得到 token)。如果 denoiser 用 v-prediction,它输出的是速度向量,这和”预测 $\boldsymbol{x}$”这件事在语义上不对齐,权重共享就会失效——实验中 v-prediction + shared weights 确实效果很差。
5. CFG:连续空间带来的”免费”能力
5.1 什么是 CFG?
CFG(Classifier-Free Guidance,无分类器引导)是图像生成里的利器,简单说就是:
“让模型沿着条件方向走得更远一点,牺牲一点多样性,换来更高的生成质量。”
数学上,CFG 在 Flow Matching 里定义为:
\[\boldsymbol{v}_\text{cfg}(\boldsymbol{z}_t | \boldsymbol{c}) = \omega \cdot \boldsymbol{v}(\boldsymbol{z}_t | \boldsymbol{c}) + (1-\omega) \cdot \boldsymbol{v}(\boldsymbol{z}_t | \varnothing)\]$\omega > 1$ 时,有条件的预测被放大,无条件的被压缩——相当于”更使劲地朝条件方向去”。
这个操作的本质是对连续向量的线性外推,在连续空间里完全自然。但在离散 DLM 里,token 分布上做线性外推没有清晰的含义,CFG 效果很差——这是离散 DLM 的一个固有短板。
ELF 在连续空间里跑,所以直接继承了图像 diffusion 的 CFG 工具箱。
5.2 用 self-conditioning 提供 guidance 信号
标准 CFG 需要一个条件 $\boldsymbol{c}$(比如类别标签或文字 prompt)。ELF 做无条件语言生成,没有外部标签——怎么办?
用 self-conditioning:网络每步预测出的 $\hat{\boldsymbol{x}}’$ 本身可以作为下一步的条件 $\boldsymbol{c}$。训练时,50% 的概率做一次额外的 forward pass 得到 $\hat{\boldsymbol{x}}’$,然后 concat 到 $\boldsymbol{z}_t$ 上再做一次预测:
\[\hat{\boldsymbol{x}} = \text{net}_\theta(\boldsymbol{z}_t \| \hat{\boldsymbol{x}}', t)\]另外 50% 的概率,用全零向量 $\mathbf{0}$ 替代 $\hat{\boldsymbol{x}}’$(模拟无条件)。推理时,每步用上一步的预测当 $\hat{\boldsymbol{x}}’$,不增加任何额外 forward pass。
5.3 Training-time CFG:推理只跑一次
标准 CFG 推理时需要两次 forward pass(一次有条件,一次无条件),overhead 翻倍。ELF 用 training-time CFG:训练时让网络直接输出”已经融合了 CFG 权重”的预测结果,推理时一次 forward 搞定。CFG scale $\omega$ 作为输入条件(4 个 control token)告诉网络,推理时改变这几个 token 就能调节质量-多样性 trade-off,不需要改模型架构。
6. 训练和推理细节(Appendix 精华)
6.1 完整训练 pipeline
下图(Figure 9)是 ELF 完整的训练流程:
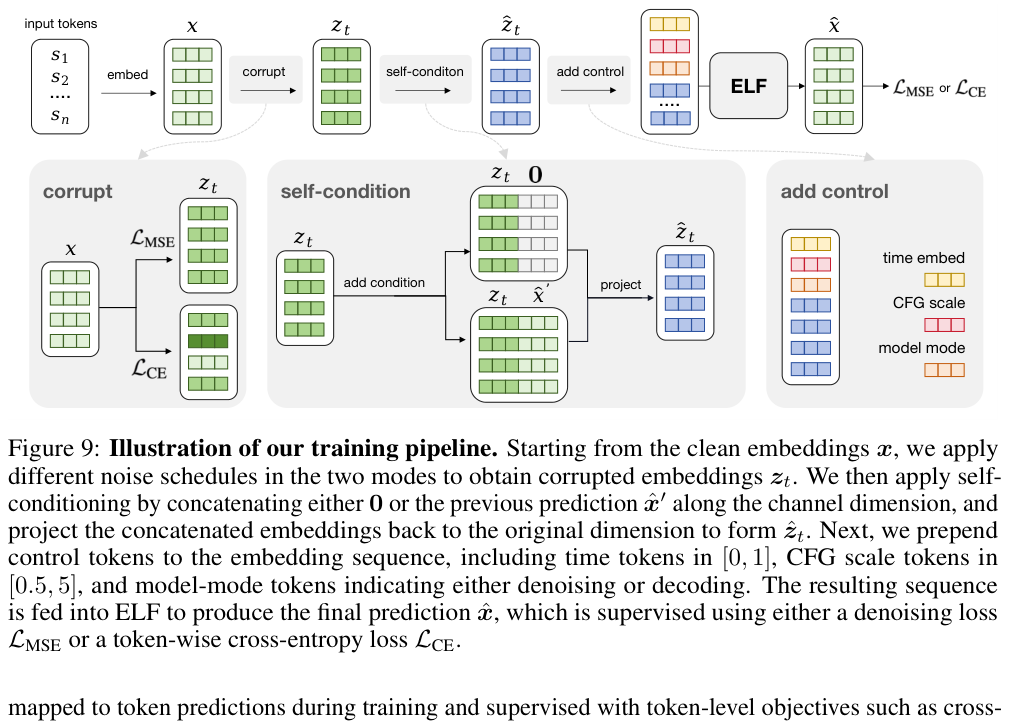
完整流程:Token 序列 → T5 encoder → 干净 embedding $\boldsymbol{x}$ → 加噪得到 $\boldsymbol{z}_t$ → self-conditioning → 拼接 control tokens(time、CFG scale、mode)→ ELF 网络 → 按 mode 计算 MSE 或 CE loss。
6.2 最后一步的特殊处理
最后一步($t=1$)理论上输入是干净 embedding,但这样模型在推理时没法泛化——因为推理时的最后一步输入是”ODE 跑出来的、不完美的 embedding”,不是真正干净的。
解决方案:训练时故意对 decode 分支的输入做 per-token 随机损坏:
\[\tilde{\boldsymbol{z}} = p \cdot \boldsymbol{x} + (1-p) \cdot \boldsymbol{\epsilon}, \quad p \sim \text{LogitNormal}(0.8, 0.8)\]每个 token 的损坏程度 $p$ 不同(而不是整个序列统一),逼迫 decoder 学会从周围上下文里恢复被损坏的 token,更贴近推理时的真实场景。
6.3 简洁的训练和推理伪代码(Algorithm 1 & 2)
论文正文里有两个简洁的伪代码(Algorithm 1 训练、Algorithm 2 推理),清晰展示了 ELF 的两分支设计:

核心逻辑:训练时以一定概率走 denoise 分支(MSE loss)或 decode 分支(CE loss);推理时用 Euler 步迭代 ODE,最后一步切 decode 模式 argmax。
6.4 带完整 guidance 的训练和推理算法(Appendix)
Appendix 里的 Algorithm 3 是加入了 self-conditioning CFG 的完整训练算法:
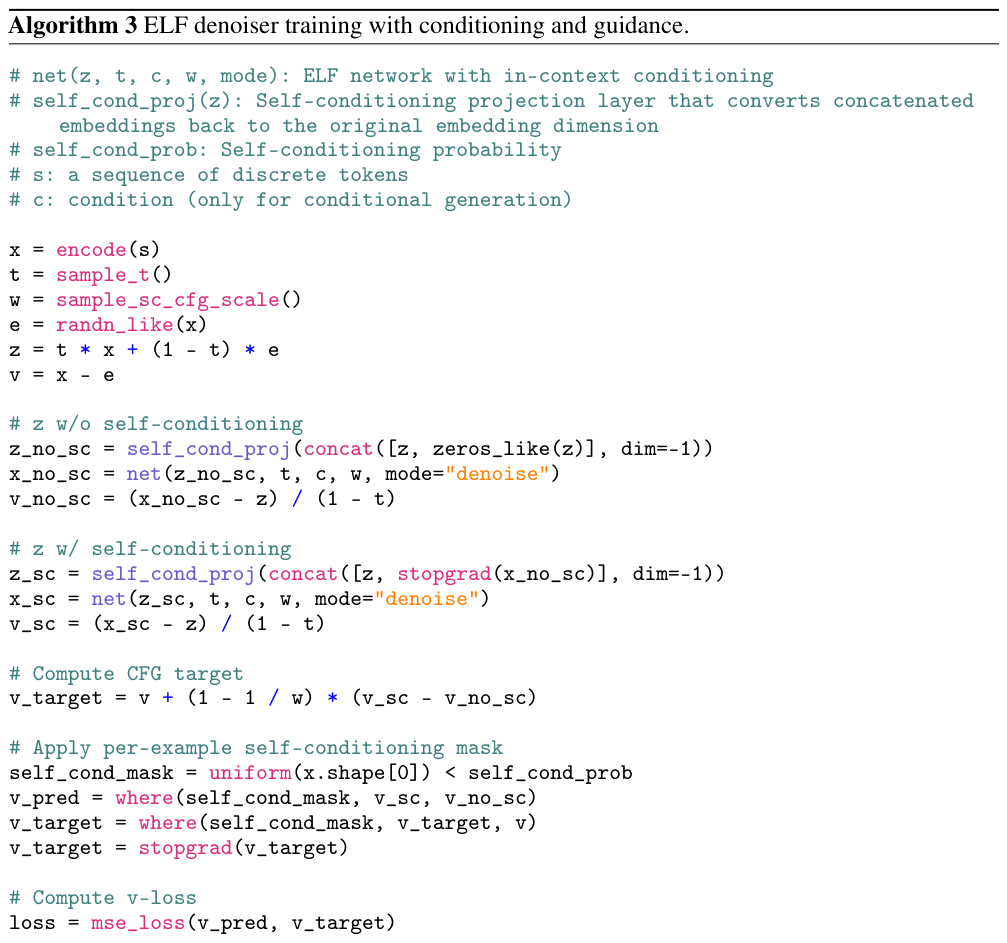
Algorithm 5 是完整推理算法(含 guidance):

6.5 ODE vs SDE 采样器(Algorithm 6)
除了确定性 ODE 采样,ELF 还支持 SDE-inspired 随机采样器:

SDE 变体的思路:每步 ODE update 之前,往 $\boldsymbol{z}_t$ 里重新注入一点高斯噪声(强度由 $\gamma$ 控制),时间 $t$ 也相应往 noise 方向偏移一点。效果是:错误的去噪轨迹有机会被”抖一抖”,不至于一错到底。
$\gamma=0$ 时退化为 ODE。实验显示 SDE sampler 在 few-step 场景(8-32 步)显著优于 ODE,而 ODE 在步数足够多时追上来。
7. 实验结果
7.1 主结果:更少训练数据,更少推理步数,更好效果

上图是 ELF-B(105M 参数)与四个主流 baseline(约 170M 参数)的对比。纵轴是 Gen. PPL(生成 perplexity,越低越好),横轴是采样步数。
ELF-B 在 32 步就达到 Gen. PPL = 24,远好于 MDLM/Duo/FLM/LangFlow 即使用 1024 步的结果。
数据量:ELF 用了 45B tokens(OWT 跑 5 个 epoch),对比方法用了 524B+ tokens,整整少了 10 倍多。
7.2 与蒸馏方法对比、System-level 分析
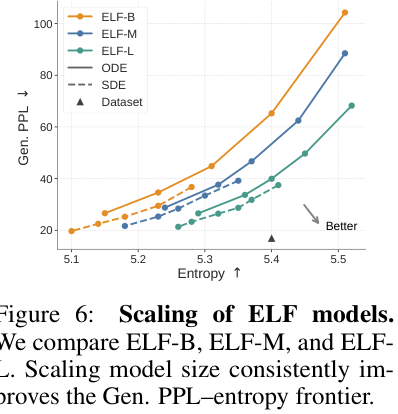
详细 system-level 对比见下图(Figure 6 是 scaling,Figure 7 是系统对比):
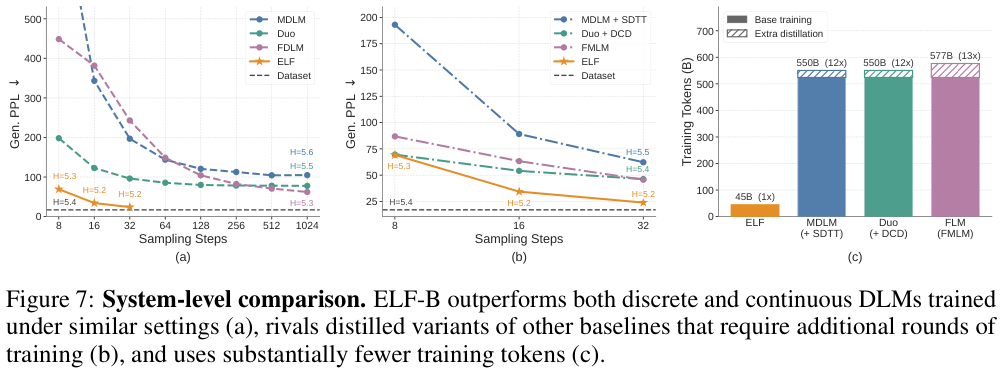
值得注意的是,ELF 不使用任何蒸馏,但在 few-step 场景下仍然超越经过蒸馏的 MDLM+SDTT、Duo+DCD、FMLM。蒸馏方法需要额外训练轮次,ELF 更干净。
模型 scaling 结果(Figure 6):ELF-B (105M) → ELF-M (342M) → ELF-L (652M),Gen. PPL 随规模持续下降,scaling 有效。
7.3 各项消融实验
下图(Figure 4 和 Figure 5)是消融实验结果,每条曲线通过扫 CFG scale 得到(即 quality-diversity trade-off 的 Pareto frontier):
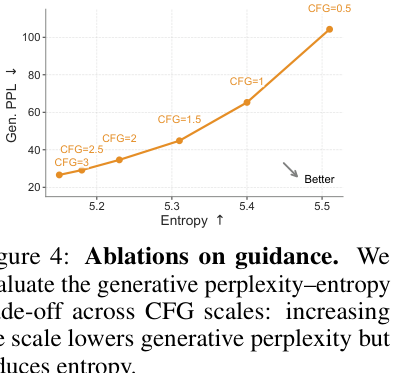
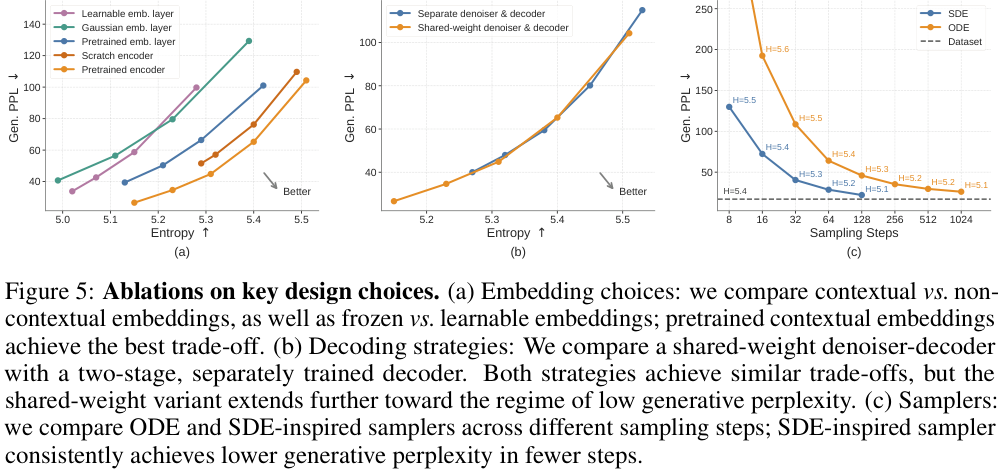
几个关键结论:
- CFG scale(Figure 4):增大 $\omega$ → Gen. PPL 下降(质量↑)但 entropy 下降(多样性↓),经典 trade-off
- Embedding 选择(Figure 5a):预训练 contextual embedding(T5)> scratch encoder > frozen Gaussian > learnable embedding。learnable 最差,因为 embedding 和 denoiser 联合优化太难
- Decoding 策略(Figure 5b):shared-weight 和 separate decoder 效果接近,但 shared-weight 在低 PPL 区间更优
- Sampler(Figure 5c):SDE sampler 在 few-step 显著优于 ODE
7.4 条件生成(翻译 + 摘要)
ELF 在 WMT14 De-En 翻译(BLEU 26.4)和 XSum 摘要(R-1/R-2/R-L = 36.0/12.2/27.8)上全面超越 MDLM、Duo、E2D2、SeqDiffuSeq、CDCD:
| 方法 | Params | BLEU (De-En) | R-1 | R-2 | R-L |
|---|---|---|---|---|---|
| AR | 99M | 25.2 | 30.5 | 10.2 | 24.4 |
| MDLM | 99M | 18.4 | 33.4 | 11.6 | 25.8 |
| Duo | 170M | 21.3 | 31.4 | 10.1 | 25.0 |
| E2D2 | 99M | 24.8 | 28.4 | 8.3 | 22.0 |
| ELF (ours) | 105M | 26.4 | 36.0 | 12.2 | 27.8 |
8. 个人感想
ELF 的贡献用一句话总结:把图像 diffusion 的成熟工具箱(Flow Matching、x-prediction、training-time CFG、SDE sampler)几乎原封不动地搬到语言生成,同时用”最后一步才 token”这个极简设计解决了连续-离散接口问题。
这件事听起来简单,但它揭示了一个重要 insight:连续 DLM 之前差,不是因为”文字天生离散”这个无法绕开的本质矛盾,而是之前大家在接口设计上选了错误的路——每步都往 token 对齐、或者用两段式训练。这些设计限制了连续空间里的流动自由度,才导致效果输给离散方案。
Kaiming He 在这篇里的角色也值得一提。他的”Back to basics”工作建立了 x-prediction 在高维数据上的理论基础,”Mean Flows”工作建立了 training-time CFG 的方法论,ELF 是这条技术路线在语言生成上的直接落地。
当然,ELF 目前规模还小(最大 652M),和 7B/70B 级别的 LLM 差距还很大。Diffusion LM 在 in-context learning、few-shot prompting 上能不能追上 AR 模型,还是开放问题。但作为连续 DLM 方向的一个重要里程碑,这篇工作的技术路线是清晰且有说服力的。
代码开源:https://github.com/lillian039/ELF,感兴趣的可以跑跑看。有问题欢迎评论区交流。