插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。
原文:ConMoE: Expert-Pool Consolidation via Prototype Reassignment for MoE Compression
你有没有想过,MoE 架构最骄傲的地方,恰恰也是最烫手的地方?
MoE(Mixture-of-Experts)的核心设计是稀疏激活——每个 token 只走少数几个 expert,理论上参数量很大但计算量很小。Qwen3-30B-A3B 的名字里 A3B 的意思就是”激活参数 3B”,但总参数有 30B。听起来很美,对吧?
但问题来了:这 30B 参数,你一个都不能少地加载进显存。
不管一个 token 实际上只用了 3B 参数,那剩下 27B 的专家还是得老老实实待在显存里候命。这就是 MoE 推理的核心矛盾:稀疏激活省了算力,但显存一分没省。随着模型越做越大,expert 存储变成了 MoE 落地的最大障碍之一。
现有的压缩思路主要两条路:剪掉专家(pruning) 和 合并专家(merging)。前者直接删掉一些专家,后者把多个专家的权重”揉”成一个新专家。
今天要聊的这篇论文提了第三条路:什么都不删,什么都不合并,只是把原来的专家引用”重新指向”一个更小的专家池。
听起来像绕口令?别急,慢慢来。
在聊 ConMoE 之前,先交代下背景,说说 pruning 和 merging 各自的问题。
Expert Pruning(专家剪枝):直接删掉贡献低的专家。简单粗暴,但问题是删了就是删了,原来指向这个专家的 router 决策没有任何”容错”——被删专家的那些 token 只能丢给其他留下来的专家,不管合不合适。
Expert Merging(专家合并):把多个专家的权重融合成一个新专家。听起来更优雅,但实际上构造了一个”原来不存在”的新权重,这个新权重可能引入了原本没有的错误,而且融合方式很敏感,调参难度大。
这两类方法有一个共同问题:把”保留哪些专家参数”和”原来的 expert slot 该怎么被表示”这两件事耦合在一起了。
ConMoE 的作者们说,等等,这两个问题应该分开来看。
论文提出了一个新的框架视角,叫 expert-pool consolidation(专家池整合)。
核心思想拆成两步:
这样,router 对外还是看到原来那些 expert slot,内部只是把调用转发给对应的 prototype。专家的权重没有被修改,没有被融合,prototype 就是原来的 pretrained 专家。
如下图,直观地展示了 ConMoE 的整体流程:
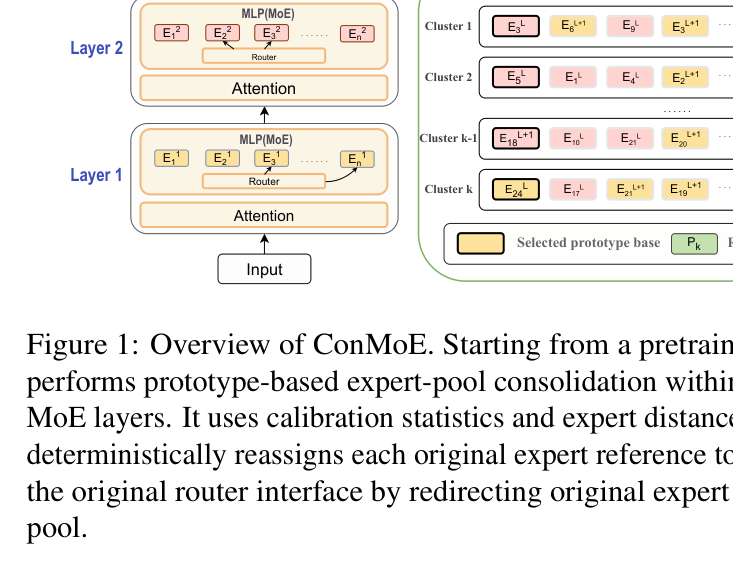
图里的流程很清晰:左边是预训练的 MoE,有若干层,每层有自己的专家池。ConMoE 在若干相邻层构成的 local scope 里,用 calibration 统计数据和专家间的距离来选出 prototype,然后把原来的每个专家 slot 都确定性地指向某个 prototype。最右边压缩后的 MoE 对外接口和原来一样(router 不变),只是内部的专家池变小了。
这里有一个很巧妙的地方:prototype 可以跨层共享。也就是说,相邻几层的专家可以共用一个 prototype 池,这让压缩比更高,同时也利用了相邻层之间专家的冗余性。
这是方法里最关键的设计。对于每个 local scope $G$,ConMoE 给每个专家算一个分数 $s_e$,然后取 top-K 作为 prototype。
分数由两个信号构成:
信号一:路由条件贡献分(contribution score)$a_e$
\[a_e = \frac{1}{|\mathcal{D}_e|} \sum_{t \in \mathcal{D}_e} g_e(t) \cdot \|e(h_t)\|_2\]说人话:在 calibration 数据上,这个专家被 router 选中的那些 token,它的输出强度乘以路由权重的平均值。分数高 = 这个专家被用到时贡献大。
信号二:可替换性分(replaceability score)$b_e$
\[b_e = \min_{e' \in \mathcal{E}_G \setminus \{e\}} d(e, e')\]就是这个专家在 scope 内,到其最近邻专家的距离。距离越大 = 越难被其他专家替代 = 越不可替换。
两个分数各自在 scope 内做 min-max 归一化后相乘:
\[s_e = \bar{a}_e \cdot \bar{b}_e\]直觉很清晰:一个好的 prototype,既要在原来模型里有实质性的贡献(不能是闲置专家),又要在参数空间里相对独特(不能被其他专家轻易替代)。两个维度同时满足,才是值得被保留的 prototype。
选好 prototype 后,每个原始专家就找自己最近的 prototype:
\[m_G(e) = \arg\min_{p \in P_G} d(e, p)\]这就是重映射。干净,确定,不需要梯度,不需要 fine-tune。
ConMoE 允许相邻几层共享一个 prototype 候选池(local scope),这让压缩更灵活。但 scope 到底设多大合适?
如下图是在 Qwen3-30B-A3B 上做的消融,50% expert reduction 的情况下,不同 scope size 的效果:
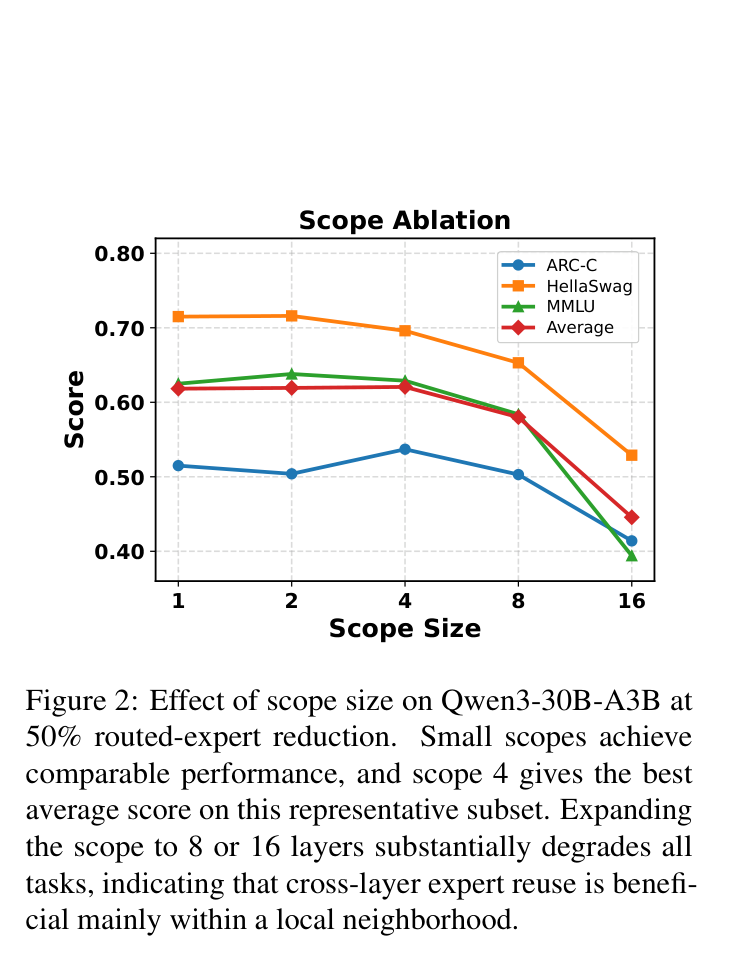
结果很有趣:scope 1(只在单层内选)、scope 2、scope 4 的表现非常接近,scope 4 在这个代表性子集上平均分最高。但 scope 一旦扩到 8 或 16 层,三个任务的性能都出现明显下降,HellaSwag 和 MMLU 掉得尤其多。
这说明什么?相邻层之间确实存在可复用的冗余,但这种冗余是局部的。距离太远的层,对应的是模型不同深度的语义转换,强行共享 prototype 会引入深度不匹配的问题。
这也解释了为什么 ConMoE 选择 bounded local scope,而不是一个全局的 expert pool。
实验在三个 MoE 模型上做了对比:Qwen3-30B-A3B、deepseek-moe-16b-base、OLMoE-1B-7B-0125,各自测了 25% 和 50% 的 expert reduction。Baseline 包括:
如下表是主要实验结果(6 个多选题 benchmark 的平均分):

几个关键观察:
整体来说,ConMoE 作为一种全新的”不删不合并、只重映射”的压缩范式,在和 pruning/merging 同等压缩比下能打平甚至超过,这本身就是一个有意义的结论。
如下表对比了不同的整合方式:
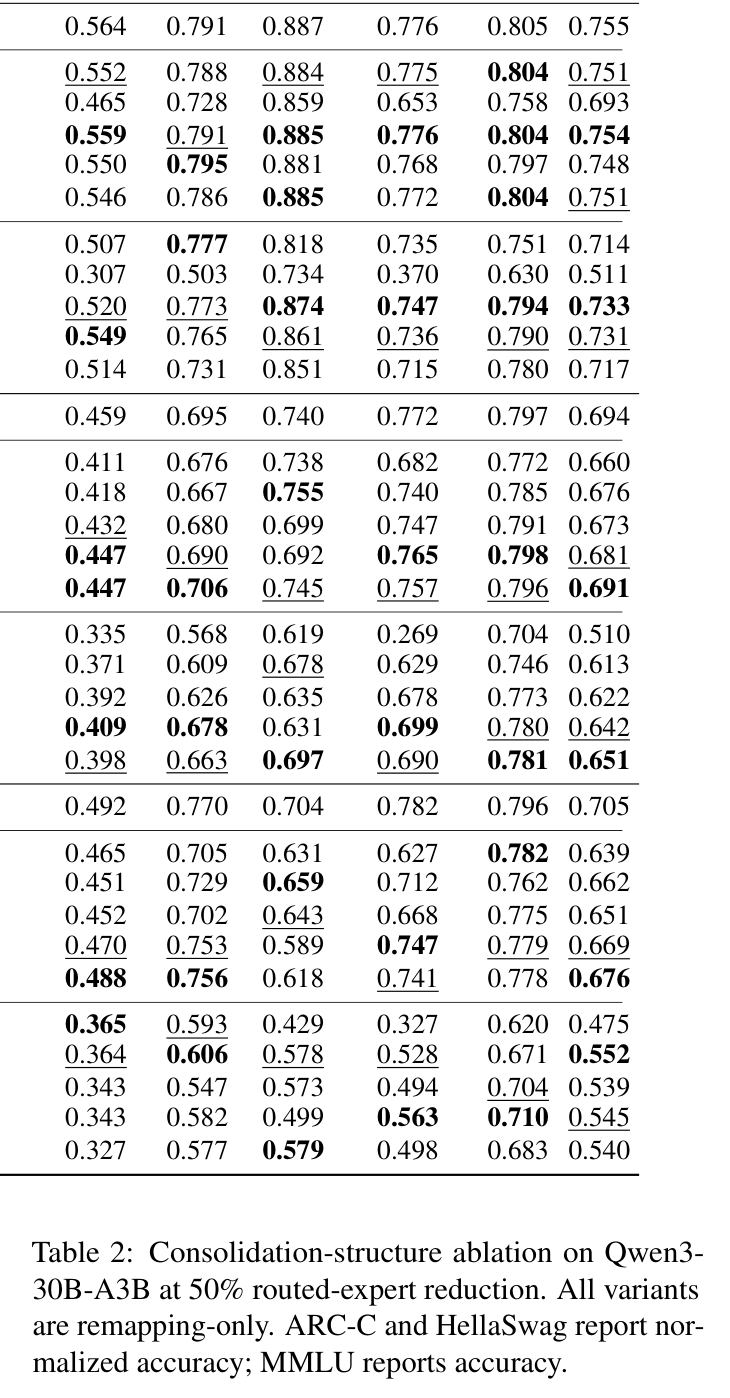
三种 variant:
有意思的是,layer-local 已经很强了(ARC-C 0.515,HellaSwag 0.715,MMLU 0.651)。允许跨层候选池(Cross-layer fixed-k)在 HellaSwag 上略有提升,Adaptive prototype 和 Cross-layer fixed-k 表现接近。
结论:确定性重映射本身才是最重要的成分,跨层和自适应选择是锦上添花。
如下表比较了不同的 prototype 选择信号:
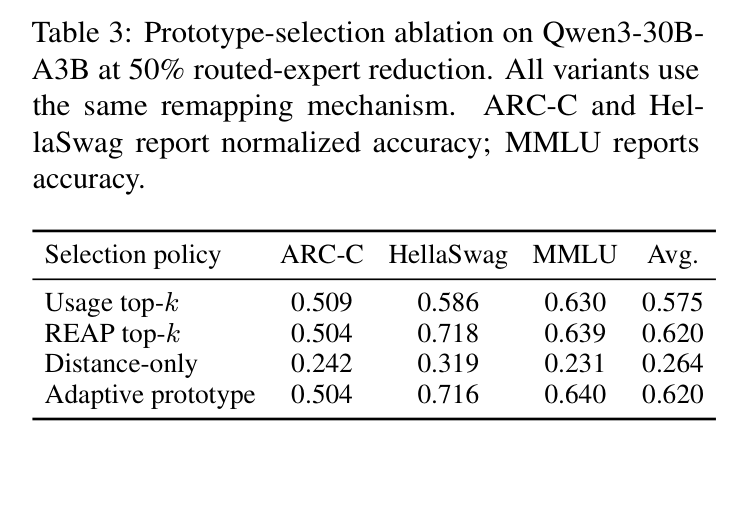
路由条件贡献分是主导信号,可替换性是辅助正则化(防止选出重复的 prototype),单独用距离作为选择标准完全行不通。
有人会问:选好 prototype 之后,能不能再做一下权重融合(把分配给同一 prototype 的那些原始专家的权重平均一下),效果会不会更好?
如下表给出了答案:
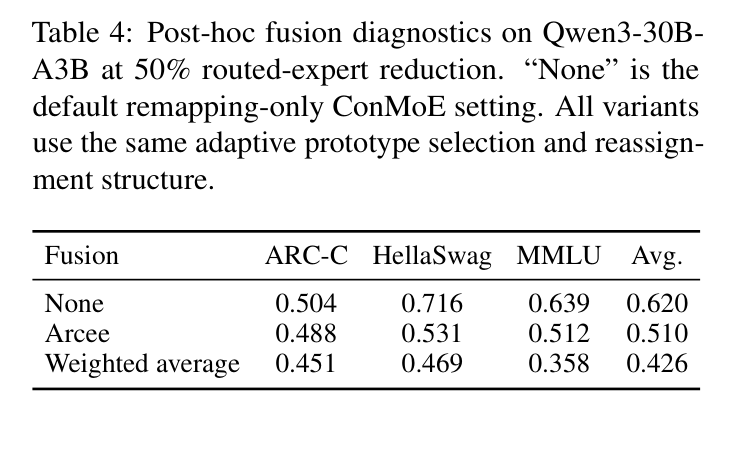
对比三种方案:
ConMoE 的收益来自确定性重映射,而不是权重融合。直接复用原始的 pretrained prototype 才是最稳的策略,加了融合反而破坏了原始权重。
为什么跨层 scope 有效,但又不能太大?论文专门做了一个几何分析。
在 Qwen3-30B-A3B 上,用 4 层 scope 计算每个 expert 在参数空间的最近邻,统计最近邻是否在同一层还是不同层:
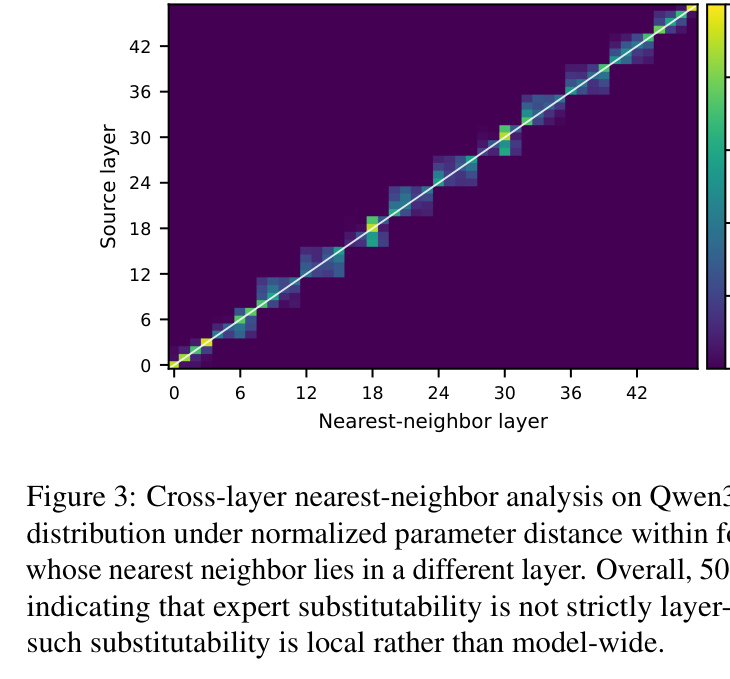
左图是热力图,展示从 source layer 到最近邻 layer 的分布。可以看到主要沿对角线集中,说明最近邻大概率在附近的层,而非全局随机分布。
右图是每层中”最近邻在不同层”的比例。整体上有 50.4% 的 expert,其参数空间的最近邻在另一层,部分中间层超过 70%。
这两个观察共同说明:专家的可替换性不是严格层内的,相邻层之间存在真实的冗余——这是跨层共享 prototype 的几何依据。但这种冗余是局部的,不支持全局共享。
ConMoE 提供了一个很干净的框架来思考 MoE 压缩:
三个设计原则从实验里验证:
个人觉得这篇论文最有价值的点,是把”保留哪些专家参数”和”原来的 expert slot 怎么被表示”这两个问题显式地解耦了。这个视角在之前的 pruning/merging 框架里是隐含的,ConMoE 把它明确化之后,整个设计空间就清晰多了。
当然 limitation 也直接:这套方案依赖 calibration 数据,跨层 scope 不能太大,而且现在的”logical reduction ratio”和实际的显存节省还需要专门的 runtime 支持(shared-prototype checkpoint 格式)才能落地。最后这点是整个 prototype sharing 方案的工程挑战,不只是这篇论文的问题。
感兴趣的可以去翻原文,代码和复现脚本作者也有提到会开源。
欢迎评论区交流,有什么遗漏或者理解有误的地方也欢迎指出~