vLLM 源码解析(二)
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

1. Block 概览
vLLM 的一个很大创新点是将物理层面的 GPU 和 CPU 可用内存切分成若干个 block,这样可以有效降低内存碎片化问题。具体而言,vLLM 的 block 分为逻辑层面(logical)和物理层面(physical),二者之间存在映射关系。下图很好解释了两个层面 block 的关系。
假设每个 block 可以用来存 4 个 token 的kv cache数据。一个句子的 token在逻辑层面是紧邻的,每次 decoding 生成新的 token 就往空闲的 block 里放。但是对应到物理层面的 block,一个句子的 token 可能分布在并不相邻的 block内,不过没关系,vLLM 会为每个句子的每个 token记录逻辑和物理block 的映射关系,方便查找和读取。
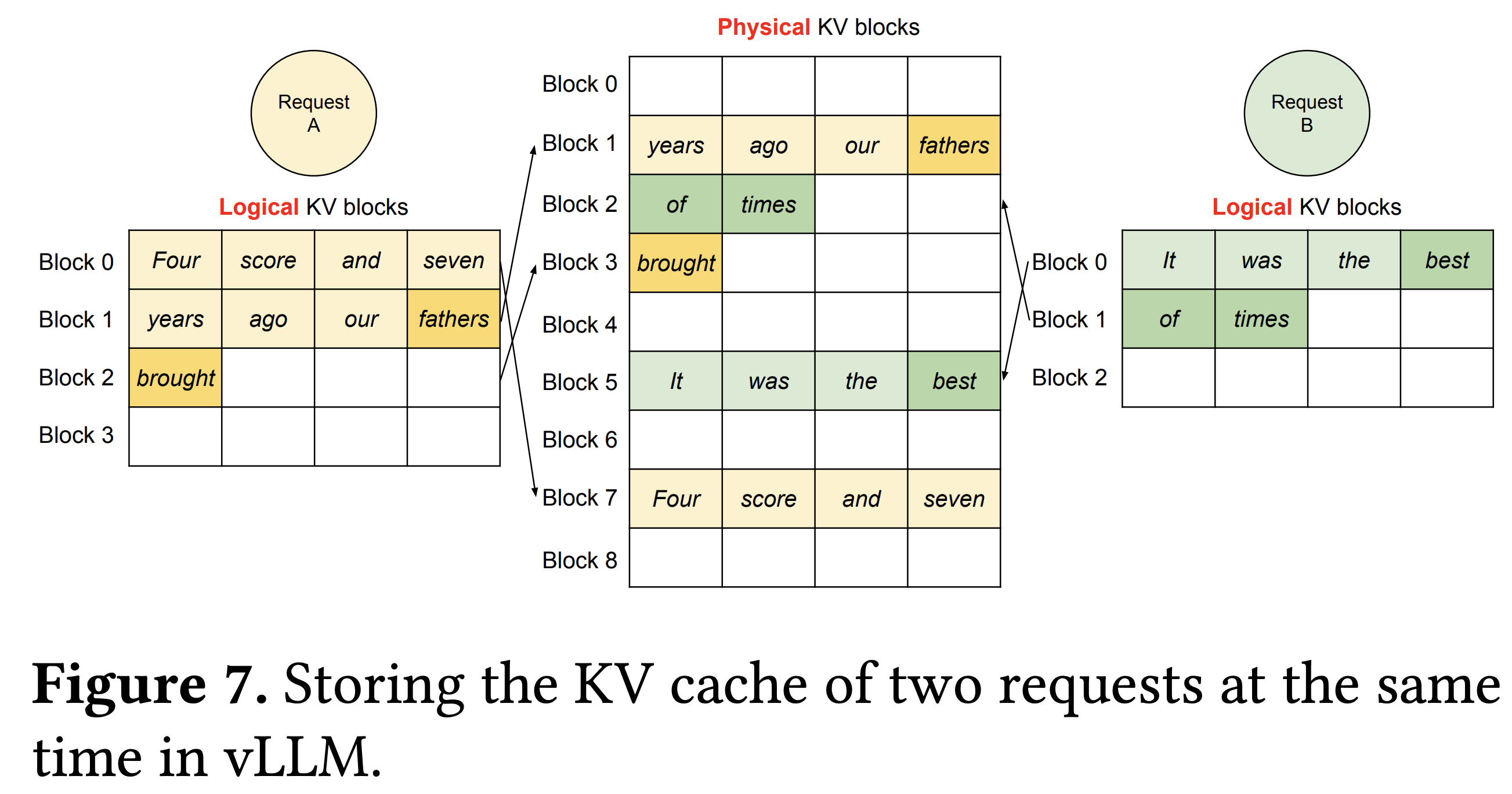
接下来我们详细介绍 block 大小的含义,以及 block 的数量是如何计算的,最后介绍 vLLM 是如何管理 block 的。
2. Block 大小如何计算
block 的大小可以自定义,上面定义为 4,简单理解就是每个 block 最多存储 4 个 token 的 kv cache 数据。但是 block 设置为 4 的时候对应到 GPU 内存到底是多大呢?其实这很好计算,
一个 block 占用内存大小(Byte)= token 数量 (block_size) ✖️ 一个 token 的 kv cache 占用 内存大小。
所以,我们只需要计算出单个 token 的 kv cache 对应的大小即可。block 大小的计算方法由vllm/vllm/worker/cache_engine.py文件里CacheEngine类的get_cache_block_size函数实现,代码也很简单,简化后如下:
# vllm/vllm/worker/cache_engine.py
class CacheEngine:
@staticmethod
def get_cache_block_size(
block_size: int,
cache_dtype: str,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
head_size = model_config.get_head_size()
num_heads = model_config.get_num_kv_heads(parallel_config)
num_layers = model_config.get_num_layers(parallel_config)
key_cache_block = block_size * num_heads * head_size
value_cache_block = key_cache_block
total = num_layers * (key_cache_block + value_cache_block)
if cache_dtype == "auto":
dtype = model_config.dtype
else:
dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_dtype]
dtype_size = _get_dtype_size(dtype)
return dtype_size * total
上面代码中首先拿到 num_heads和head_size两个变量的值, num_heads * head_size就表示单个 token 在单层多头注意力机制计算中所需要的参数量,不过这只是 key 或者 value cache 所占用的参数量。
一个 block 占用的内存 = token 数量(block_size)✖️ 层数 (num_layers) ✖️ 单层 kv cache 占用内存 (2✖️num_heads✖️head_size)✖️ 数据类型大小(如果是 fp16,则每个数据占用 2 Bytes)
举例来说,假设 block_size=4, num_layers=4, num_heads=8, heads_size=128,采用 fp16 存储数据,那么
一个 block 占用内存大小 = 4 ✖️ 4 ✖️ 8 ✖️ 128 ✖️ 2 = 32,768 Bytes。
总结,一个 block 所占用的内存大小就是 block_size 个 token kv cache 所占内存的总和。不同模型的 block 各不相同。
2. Block 数量如何计算
block 数量计算由vllm/vllm/worker/worker.py文件中Worker类的profile_num_available_blocks函数实现,该函数很简单,简化代码如下:
class Worker
@torch.inference_mode()
def profile_num_available_blocks(
self,
block_size: int,
gpu_memory_utilization: float,
cpu_swap_space: int,
cache_dtype: str,
) -> Tuple[int, int]:
torch.cuda.empty_cache()
# 这一行其实就是用模拟数据跑一下forward 来统计GPU 的使用情况
self.model_runner.profile_run()
torch.cuda.synchronize()
free_gpu_memory, total_gpu_memory = torch.cuda.mem_get_info()
peak_memory = total_gpu_memory - free_gpu_memory
cache_block_size = CacheEngine.get_cache_block_size(
block_size, cache_dtype, self.model_config, self.parallel_config)
num_gpu_blocks = int(
(total_gpu_memory * gpu_memory_utilization - peak_memory) //
cache_block_size)
num_cpu_blocks = int(cpu_swap_space // cache_block_size)
num_gpu_blocks = max(num_gpu_blocks, 0)
num_cpu_blocks = max(num_cpu_blocks, 0)
if self.model_runner.lora_manager:
self.model_runner.remove_all_loras()
gc.collect()
torch.cuda.empty_cache()
return num_gpu_blocks, num_cpu_blocks
整个函数的逻辑很清晰,简单理解就是先用模拟数据跑一次 forward 记录下 GPU 的使用情况,这样可以知道 peak memory,然后计算每个 block 需要用到的 memory,接着就可以计算出 block 数量了。具体而言:
- 13 行:vllm 默认用 256 个句子来做 profile,每个句子长度为 128
- 15 到 17 行:统计 GPU 内存使用情况,返回的是以字节(Byte)为单位的数值,后面也都是基于 Byte 为单位进行计算的
- 19 行:计算每个 block 的大小,这个在前面已经介绍。
- 20-23 行:计算可用的 GPU block 数量。
num_gpu_blocks = int( (total_gpu_memory * gpu_memory_utilization - peak_memory) // cache_block_size):gpu_memory_utilization: 默认值是 0.9,表示 GPU 内存利用率是 90%,这挺高的了。所以最终的可用 GPU block 数量等于剩余 GPU 内存大小除以每个 block 的大小 - 24 行:计算可用的 CPU block 数量。
num_cpu_blocks = int(cpu_swap_space // cache_block_size)这里的cpu_swap_space 代表每个 GPU 对应的 CPU swap 空间大小,单位是(GB),默认是是 4。也就是说每个 GPU 对应的 CPU swap 空间大小是 4 GB。
3. Block 如何管理?
3.1 逻辑 Block 定义和使用
逻辑 Block(LogicalTokenBlock)定义如下:
# vllm/vllm/block.py
class LogicalTokenBlock:
def __init__(
self,
block_number: int,
block_size: int,
) -> None:
self.block_number = block_number
self.block_size = block_size
self.token_ids = [_BLANK_TOKEN_ID] * block_size
self.num_tokens = 0
def is_empty(self) -> bool:
return self.num_tokens == 0
def get_num_empty_slots(self) -> int:
return self.block_size - self.num_tokens
def is_full(self) -> bool:
return self.num_tokens == self.block_size
def append_tokens(self, token_ids: List[int]) -> None:
assert len(token_ids) <= self.get_num_empty_slots()
curr_idx = self.num_tokens
self.token_ids[curr_idx:curr_idx + len(token_ids)] = token_ids
self.num_tokens += len(token_ids)
def get_token_ids(self) -> List[int]:
return self.token_ids[:self.num_tokens]
def get_last_token_id(self) -> int:
assert self.num_tokens > 0
return self.token_ids[self.num_tokens - 1]
- block_number: int: 这个是 PhysicalTokenBlock 实例对象的索引,可以理解成是 flag,用于区分不同 block
- block_size: int: 表示一个 block 内存储多少个 token 的 kv cache 数据。
-
__init__函数中self.token_ids初始化是一个长度为 block_size 的全为 -1 的list。后续可以通过append_tokens将新的 token添加到这个 list 中去。 -
self.num_tokens会统计已使用的 token 数量,当self.num_tokens==block_size时则表示这个 block 已经被使用完了。
逻辑 Block 的使用逻辑是根据需要实时实例化一个对象,如果当前的 LogicalBlock没有剩余空间了,就再实例化一个新的。
在 vLLm 的使用场景是在vllm/vllm/sequence.py里的Sequence类中根据需要动态创建LogicalBlock。
Sequence类在之前介绍 vLLM 的文章 【大模型推理框架 vLLM 源码解析(一)】中已经有详细介绍,这里你只需要知道这个类记录了每个输入句子整个推理过程(prefilling 和 decoding)的所有信息。
我们结合代码来看会更好理解,如下:
# vllm/vllm/sequence.py
class Sequence:
def __init__(self, ...):
...
self.logical_token_blocks: List[LogicalTokenBlock] = []
self._append_tokens_to_blocks(prompt_token_ids)
...
def _append_tokens_to_blocks(self, token_ids: List[int]) -> None:
cursor = 0
while cursor < len(token_ids):
if not self.logical_token_blocks:
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
if last_block.is_full():
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
num_empty_slots = last_block.get_num_empty_slots()
last_block.append_tokens(token_ids[cursor:cursor +
num_empty_slots])
cursor += num_empty_slots
def _append_logical_block(self) -> None:
block = LogicalTokenBlock(
block_number=len(self.logical_token_blocks),
block_size=self.block_size,
)
self.logical_token_blocks.append(block)
-
__init__函数中会初始化self.logical_token_blocks空数组,用来存LogicalBlock。可以看到会先将 prompt 的所有 token 通过_append_tokens_to_blocks存入到 block 中 -
_append_tokens_to_blocks函数会遍历传入的 token_ids 数组中的每个 token id,将该 token 信息存入到 LogicalBlock 中。- 第 12 行:如果
self.logical_token_blocks为空,则会动态调用_append_logical_block来创建一个LogicalBlock,并存到self.logical_token_blocks变量中去 - 第 16 行:如果最新创建的
LogicalBlock空间已经满了,则同样会动态调用_append_logical_block来创建一个新的LogicalBlock
- 第 12 行:如果
3.2 物理Block 定义和管理
物理 Block (PhysicalTokenBlock)的代码定义如下:
- device: Device: 是一个 enum.Enum 实例对象,要么是 CPU 要么是 GPU。
- self.ref_count 变量用来指示这个 block 被使用的次数,默认为 0,代表没有使用。可以大于等于1,表示这个 block 内 token的 cache 被重复利用,使用场景比如可以是 beam search,这样可以重复利用cache,减少内存开销。
# vllm/vllm/block.py
class PhysicalTokenBlock:
def __init__(
self,
device: Device,
block_number: int,
block_size: int,
) -> None:
self.device = device
self.block_number = block_number
self.block_size = block_size
self.ref_count = 0
def __repr__(self) -> str:
return (f'PhysicalTokenBlock(device={self.device}, '
f'block_number={self.block_number}, '
f'ref_count={self.ref_count})')
PhysicalTokenBlock只是针对单个 block 的描述。vLLM 在vllm/vllm/core/block_manager.py文件下实现了BlockAllocator类用来初始化所有物理 block,并负责分配这些 block。
BlockAllocator这个类代码很简单,如下。主要作用有三个:
-
__init__: 初始化指定数量的物理层面 block,这个数量在前面一节已经介绍过如何计算。 -
allocate: 通过 list的 pop() 函数返回一个可用的 block,并将该 block 的ref_count设置为 1 -
free:回收一个指定的PhysicalBlock,但是回收的前提是这个 block 的ref_count变量值为 0,表示这个 block 内的 token kv cache 数据不再需要了。# vllm/vllm/core/block_manager.py class BlockAllocator: def __init__( self, device: Device, block_size: int, num_blocks: int, ) -> None: self.device = device self.block_size = block_size self.num_blocks = num_blocks # Initialize the free blocks. self.free_blocks: BlockTable = [] for i in range(num_blocks): block = PhysicalTokenBlock(device=device, block_number=i, block_size=block_size) self.free_blocks.append(block) def allocate(self) -> PhysicalTokenBlock: if not self.free_blocks: raise ValueError("Out of memory! No free blocks are available.") block = self.free_blocks.pop() block.ref_count = 1 return block def free(self, block: PhysicalTokenBlock) -> None: if block.ref_count == 0: raise ValueError(f"Double free! {block} is already freed.") block.ref_count -= 1 if block.ref_count == 0: self.free_blocks.append(block) def get_num_free_blocks(self) -> int: return len(self.free_blocks)
3.3 Block 管理和映射模块
在介绍这个Block 管理模块之前,我们先了解 vLLM 中设置的用来判断句子是否能够被分配物理 Block 的三种状态,代码如下:
# vllm/vllm/core/block_manager.py
class AllocStatus(enum.Enum):
"""Result for BlockSpaceManager.can_allocate
"""
OK = enum.auto()
LATER = enum.auto()
NEVER = enum.auto()
三种状态的含义如下:
-
OK: seq_group 可以现在被分配。 -
LATER: seq_group 不能被分配。分配器的容量大于 seq_group 所需。 -
NEVER: seq_group 永远不能被分配。seq_group 太大,无法在 GPU 中分配。
vllm/vllm/core/block_manager.py下的BlockSpaceManager是一个高级内存管理器,它在内存密集型计算任务(尤其是在使用GPU和CPU进行大规模数据处理的情况下)中管理逻辑数据块和物理内存块之间的映射。
接下来,我们结合代码介绍BlockSpaceManager一些重要的函数。
- 初始化函数
__init__:-
watermark: 一种阈值机制,用来决定何时停止在GPU上分配新的块,以避免内存不足 -
watermark_blocks: 计算出在达到内存不足前,还能在GPU上分配多少个块。 -
sliding_window: 可选参数,用来限制在任意给定时间内活跃的逻辑块的数量,有助于控制内存使用。 - 创建了 cpu 和 gpu 两种
BlockAllocator,不过需要注意这里都是物理层面的 Block - 创建了一个字典
block_tables,用于存储每个 sequence id 和它所使用的物理块之间的映射。通过这个 sequence id ,我们就能找到对应的前面介绍的Sequence实例化对象,通过这个字典,就建立了逻辑 block 和物理 block 的映射关系。
-
# vllm/vllm/core/block_manager.py
class BlockSpaceManager:
def __init__(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01,
sliding_window: Optional[int] = None,
) -> None:
self.block_size = block_size
self.num_total_gpu_blocks = num_gpu_blocks
self.num_total_cpu_blocks = num_cpu_blocks
self.block_sliding_window = None
if sliding_window is not None:
assert sliding_window % block_size == 0, (sliding_window,
block_size)
self.block_sliding_window = sliding_window // block_size
self.watermark = watermark
assert watermark >= 0.0
self.watermark_blocks = int(watermark * num_gpu_blocks)
self.gpu_allocator = BlockAllocator(Device.GPU, block_size,
num_gpu_blocks)
self.cpu_allocator = BlockAllocator(Device.CPU, block_size,
num_cpu_blocks)
# Mapping: seq_id -> BlockTable.
self.block_tables: Dict[int, BlockTable] = {}
-
can_allocateclass BlockSpaceManager: def can_allocate(self, seq_group: SequenceGroup) -> AllocStatus: seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0] num_required_blocks = len(seq.logical_token_blocks) if seq_group.prefix is not None and seq_group.prefix.allocated: num_required_blocks -= seq_group.prefix.get_num_blocks() if self.block_sliding_window is not None: num_required_blocks = min(num_required_blocks, self.block_sliding_window) num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks() # Use watermark to avoid frequent cache eviction. if (self.num_total_gpu_blocks - num_required_blocks < self.watermark_blocks): return AllocStatus.NEVER if num_free_gpu_blocks - num_required_blocks >= self.watermark_blocks: return AllocStatus.OK else: return AllocStatus.LATER
can_allocate方法用于判断一个序列组(seq_group)是否能被成功分配所需的内存块。此方法首先计算该序列组基于当前任务的逻辑数据块所需的总物理内存块数量。接着,它会检查GPU分配器中的空闲内存块数量,以确认是否有足够的资源满足需求。
方法中引入了watermark_blocks概念,其主要目的是防止因频繁进行内存块的缓存淘汰而影响系统性能。在模型训练或数据处理的动态环境中,内存需求持续变化,如果因缺乏足够的空闲内存块而不得不频繁淘汰并重新分配内存块,将会造成性能损耗。这是因为被淘汰的内存块很可能很快再次需要使用,其重新分配过程会消耗额外的时间和资源。
通过设置watermark_blocks阈值,当GPU上的空闲内存块数量低于此阈值时,系统将避免分配新的内存块,以留出缓冲区域,减少缓存淘汰的发生。只有当空闲内存块数量高于此阈值时,系统才会继续进行新的内存块分配。这种策略旨在平衡内存分配需求和系统性能,避免因频繁的内存操作而降低效率。
如果根据当前的资源状态,确定序列组所需的内存块永远无法被满足,则返回AllocStatus.NEVER,意味着该序列组在当前条件下无法被分配。如果当前不可分配但未来有可能,返回AllocStatus.LATER,表明序列组暂时无法分配,但随着系统状态的改变,可能在将来能够分配。如果有足够的空闲内存块满足分配需求,则返回AllocStatus.OK,表示序列组可以立即被分配所需内存。
这种方式确保了watermark_blocks在满足内存分配需求的同时,有效避免了频繁的缓存淘汰问题,从而优化了整体的系统性能和资源利用效率。
-
allocate代码有简化,但是不影响理解class BlockSpaceManager: def allocate(self, seq_group: SequenceGroup) -> None: seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0] num_prompt_blocks = len(seq.logical_token_blocks) block_table: BlockTable = [] for logical_idx in range(num_prompt_blocks): block = self.gpu_allocator.allocate() block.ref_count = seq_group.num_seqs() block_table.append(block) for seq in seq_group.get_seqs(status=SequenceStatus.WAITING): self.block_tables[seq.seq_id] = block_table.copy()allocate方法用于为序列组分配内存块。它会遍历序列组中的每个序列,为每个序列分配足够的内存块,并将这些块添加到序列的块表中。同时,它会更新序列的块表,以便在后续的训练过程中可以正确地访问这些块。
BlockSpaceManager还有很多其它的函数,为了避免文章累赘,这里不做详细介绍。
后面会继续写一篇 vLLM 的调度Scheduler模块的文章,对BlockSpaceManager更加详细地介绍。相信通过本篇文章,你应该能够对 vLLM 的 block 有一个清楚的了解了,如果还是不清楚,可以反复阅读直到清楚为止。
参考
- https://zhuanlan.zhihu.com/p/681018057
- https://zhuanlan.zhihu.com/p/656939628
- https://zhuanlan.zhihu.com/p/655561941
- https://zhuanlan.zhihu.com/p/658233994
- https://zhuanlan.zhihu.com/p/641999400