vLLM 源码解析(一)
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

1. Quick Start
创建如下代码,命名为 run.py
from vllm import LLM, SamplingParams
prompts = [
"Have you followed marsggbo in Zhihu?",
"你一键三连了吗?"
] # 输入prompts
sampling_params = SamplingParams(temperature=0.8, top_k=50) # 采样策略
llm = LLM(model="facebook/opt-125m", tensor_parallel_size=2) # 初始化 LLM
outputs = llm.generate(prompts, sampling_params) # 完成推理
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
执行命令:python run.py。该脚本会自动将模型以张量并行的方式在两个 GPU 上进行推理计算。
整个推理过程大大致流程如下图所示,即
- 1 给定一定数量的 prompts(字符串数组)
-
- vllm 会使用 Scheduler 模块自动对需要推理句子进行调度
-
- 根据调度的结果,使用 tokenizer 将字符串转换成 prompt id,然后喂给 model 进行计算得到 logits 预测结果
-
- 根据 logits 预测结果和提前设置好的采样策略对结果进行采样得到新的 token id
-
- 将采样结果保存到 output

2. 整体核心模块
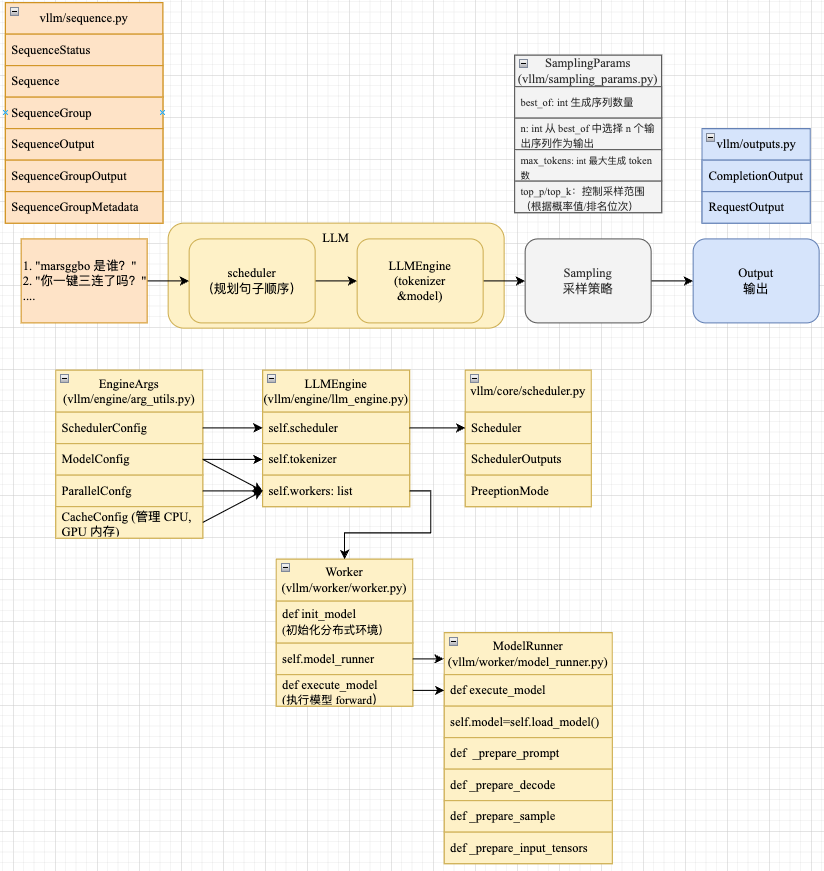
上图给出了 vLLM 核心模块之间的结构关系。接下来我们从简单的模块(即输入、采样和输出)开始介绍,最后详细介绍 LLM 模块。
3. Sequence

如上图我们可以看到 vLLM 为输入的句子设计了很多子模块,这些模块的用处各不相同,但是有彼此之间有关系,下面分别详细介绍一下。
3.1 SequenceStatus
首先看到 SequenceStatus,其源代码如下:
class SequenceStatus(enum.Enum):
"""Status of a sequence."""
WAITING = enum.auto() # 等待中,句子还没开始推理,或者推理还未结束
RUNNING = enum.auto() # 运行中
SWAPPED = enum.auto() # 已交换
FINISHED_STOPPED = enum.auto() # 已停止
FINISHED_LENGTH_CAPPED = enum.auto() # 已长度限制
FINISHED_ABORTED = enum.auto() # 已中止
FINISHED_IGNORED = enum.auto() # 已忽略
@staticmethod
def is_finished(status: "SequenceStatus") -> bool:
# 判断状态是否为已停止、已长度限制、已中止或已忽略
return status in [
SequenceStatus.FINISHED_STOPPED,
SequenceStatus.FINISHED_LENGTH_CAPPED,
SequenceStatus.FINISHED_ABORTED,
SequenceStatus.FINISHED_IGNORED,
]
3.2 SequenceData
SequenceData 用于存储与序列相关的数据。这个类有三个属性:prompt_token_ids(提示词的标记ID)、output_token_ids(生成文本的标记ID)和cumulative_logprob(累计对数概率)。
class SequenceData:
def __init__(
self,
prompt_token_ids: List[int],
) -> None:
self.prompt_token_ids = prompt_token_ids
self.output_token_ids: List[int] = []
self.cumulative_logprob = 0.0
3.3 Sequence
Sequence 用于存储序列的数据、状态和块信息,且每个序列有唯一标识,即seq_id。注意看下面的代码:
- 数据其实是通过上面的
SequenceData保存的 - 默认初始化状态,所有句子序列的状态都是
SequenceStatus.WAITING - 所谓块信息,其实就是 vLLM 会在初始化阶段预留出一定数量的CPU 和 GPU 内存,一般是以 token 为单位的,例如在初始化的时候会使用值全为 0,大小为 (256, 128)的 prompt_ids做 warm up。每个序列会按照实际大小申请 block 来记录内存使用情况,即序列 token 数越多,属性
logical_token_blocks包含的 block 个数也就越多。 -
class Sequence: def __init__( self, seq_id: int, prompt: str, prompt_token_ids: List[int], block_size: int, ) -> None: self.seq_id = seq_id self.prompt = prompt self.block_size = block_size self.data = SequenceData(prompt_token_ids) # 数据 self.logical_token_blocks: List[LogicalTokenBlock] = [] # Initialize the logical token blocks with the prompt token ids. self._append_tokens_to_blocks(prompt_token_ids) # 块信息 self.status = SequenceStatus.WAITING # 状态 ...
3.3 SequenceGroup
Sequence只是单个序列的表示方式,seq_id是它的唯一标识。SequenceGroup则是为了表示多个序列,request_id是它的唯一标识,表示是第几个请求。
具体而言,可以看到__init__函数有个参数是 seqs: List[Sequence],它表示由一个或多个 Sequence 组成的列表,然后会通过self.seqs_dict = {seq.seq_id: seq for seq in seqs}转化成字典方便管理,这个字典的 key 是每个 Sequence 的唯一标识seq_id。
class SequenceGroup:
def __init__(
self,
request_id: str,
seqs: List[Sequence],
sampling_params: SamplingParams,
arrival_time: float,
lora_request: Optional[LoRARequest] = None,
prefix: Optional[Prefix] = None,
) -> None:
self.request_id = request_id
self.seqs_dict = {seq.seq_id: seq for seq in seqs}
self.sampling_params = sampling_params
self.arrival_time = arrival_time
...
下面是 vLLm 中 LLMEngine 使用 Sequence 和 SequenceGroup 的场景示例:
class LLMEngine:
def add_request(
self,
request_id: str,
prompt: Optional[str],
sampling_params: SamplingParams,
prompt_token_ids: Optional[List[int]] = None,
arrival_time: Optional[float] = None,
lora_request: Optional[LoRARequest] = None,
prefix_pos: Optional[int] = None,
) -> None:
prompt_token_ids = self.encode_request(
request_id=request_id,
prompt=prompt,
prompt_token_ids=prompt_token_ids,
lora_request=lora_request) # 将字符串序列转换成 id
# Create the sequences.
block_size = self.cache_config.block_size
seq_id = next(self.seq_counter)
seq = Sequence(seq_id, prompt, prompt_token_ids, block_size,
lora_request)
# Create the sequence group.
seq_group = SequenceGroup(request_id, [seq], sampling_params,
arrival_time)
# Add the sequence group to the scheduler.
self.scheduler.add_seq_group(seq_group)
可以看到SequenceGroup的seqs参数在最初阶段其实只是单个序列 ,即[seq]。但是我们知道其实一个 prompt 可以有多个输出结果,所以SequenceGroup的目的是管理一个输入 prompt的多个生成序列信息。如果我们设置SamplingParams.n=2(第 4 节会介绍),那么在推理过程中,SequenceGroup会新增一个 Sequence,这个新增的 Sequence 的 seq_id 和原来的那个 Sequence 不一样,具体的代码细节会在下一篇文章中介绍。
3.5 SequenceGroupMetadata
class SequenceGroupMetadata:
def __init__(
self,
request_id: str,
is_prompt: bool,
seq_data: Dict[int, SequenceData],
sampling_params: SamplingParams,
block_tables: Dict[int, List[int]],
) -> None:
self.request_id = request_id
self.is_prompt = is_prompt
self.seq_data = seq_data
self.sampling_params = sampling_params
self.block_tables = block_tables
...
SequenceGroupMetadata 记录了一些元信息,下面代码展示了 Scheduler 模块是如何生成这些信息的:
-
request_id就是 SequenceGroup的 request_id -
seq_data是一个字典,key 是每个 Sequence的 seq_id,value 则是对应的 data (即 SequenceData) -
block_tables也是一个字典,key 也是每个 Sequence的 seq_id,value 这是对应 Sequence 申请的 block
class Scheduler:
def schedule(self) -> Tuple[List[SequenceGroupMetadata], SchedulerOutputs]:
scheduler_outputs = self._schedule()
# Create input data structures.
seq_group_metadata_list: List[SequenceGroupMetadata] = []
for seq_group in scheduler_outputs.scheduled_seq_groups:
seq_data: Dict[int, SequenceData] = {}
block_tables: Dict[int, List[int]] = {}
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
seq_id = seq.seq_id
seq_data[seq_id] = seq.data # 单个 SequenceData
block_tables[seq_id] = self.block_manager.get_block_table(seq) # 对应Sequence的block信息
seq_group_metadata = SequenceGroupMetadata(
request_id=seq_group.request_id,
is_prompt=scheduler_outputs.prompt_run,
seq_data=seq_data,
sampling_params=seq_group.sampling_params,
block_tables=block_tables,
lora_request=seq_group.lora_request,
prefix=seq_group.prefix,
)
seq_group_metadata_list.append(seq_group_metadata)
return seq_group_metadata_list, scheduler_outputs
3.6 SequenceOutput 和 SequenceGroupOutput
SequenceOutput 和 SequenceGroupOutput的关系就类似 Sequence 和 SequenceGroup。SequenceOutput其实就是记录了上一个 输入 token id 以及对应输出的 token id。
class SequenceOutput:
def __init__(
self,
parent_seq_id: int,
output_token: int,
logprobs: Dict[int, float],
) -> None:
self.parent_seq_id = parent_seq_id
self.output_token = output_token
self.logprobs = logprobs
class SequenceGroupOutput:
def __init__(
self,
samples: List[SequenceOutput],
prompt_logprobs: Optional[PromptLogprobs],
) -> None:
self.samples = samples
self.prompt_logprobs = prompt_logprobs
4. SamplingParams

SamplingParams 包含以下参数:
-
n:要生成的序列的数量,默认为 1。 -
best_of:从多少个序列中选择最佳序列,需要大于 n,默认等于 n。 -
temperature:用于控制生成结果的随机性,较低的温度会使生成结果更确定性,较高的温度会使生成结果更随机。 -
top_p:用于过滤掉生成词汇表中概率低于给定阈值的词汇,控制随机性。 -
top_k:选择前 k 个候选 token,控制多样性。 -
presence_penalty:用于控制生成结果中特定词汇的出现频率。 -
frequency_penalty:用于控制生成结果中词汇的频率分布。 -
repetition_penalty:用于控制生成结果中的词汇重复程度。 -
use_beam_search:是否使用束搜索来生成序列。 -
length_penalty:用于控制生成结果的长度分布。 -
early_stopping:是否在生成过程中提前停止。 -
stop:要停止生成的词汇列表。 -
stop_token_ids:要停止生成的词汇的ID列表。 -
include_stop_str_in_output:是否在输出结果中包含停止字符串。 -
ignore_eos:在生成过程中是否忽略结束符号。 -
max_tokens:生成序列的最大长度。 -
logprobs:用于记录生成过程的概率信息。 -
prompt_logprobs:用于记录生成过程的概率信息,用于特定提示。 -
skip_special_tokens:是否跳过特殊符号。 -
spaces_between_special_tokens:是否在特殊符号之间添加空格。
这些参数的设置通常取决于具体需求和模型性能。以下是一些常见的设置指导方法:
-
temperature:较低的温度(如0.2)会产生更确定性的结果,而较高的温度(如0.8)会产生更随机的结果。您可以根据您的需求进行调整。 -
presence_penalty、frequency_penalty 和 repetition_penalty:这些参数可以用于控制生成结果中的词汇分布和重复程度。您可以根据您的需求进行调整。 -
use_beam_search:束搜索通常用于生成更高质量的结果,但可能会降低生成速度。您可以根据您的需求进行调整。 -
length_penalty:这个参数可以用于控制生成结果的长度。较高的值会产生更长的结果,而较低的值会产生更短的结果。您可以根据您的需求进行调整。 -
early_stopping:如果您不希望生成过长的结果,可以设置此参数为True。 -
stop 和 stop_token_ids:您可以使用这些参数来指定生成结果的结束条件。
5. Output 模块
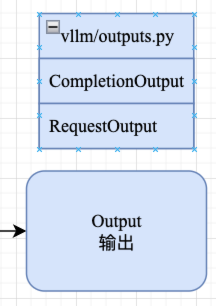
Output 主要用于表示语言模型(LLM)的生成结果,包含如下两个模块:
CompletionOutputRequestOutput
通过上面的介绍我们知道一个 request 可能包含多个序列,CompletionOutput 用来表示一个 request 中某个序列的完整输出的数据,其中下面的index就表示该序列在 request 中的索引位置
class CompletionOutput:
def __init__(
self,
index: int, # 输出结果在请求中的索引
text: str, # 生成的文本
token_ids: List[int], # 生成的文本对应的 token ID 列表
cumulative_logprob: float,
logprobs: Optional[SampleLogprobs],
finish_reason: Optional[str] = None, # 序列完成的原因(SequenceStatus)
lora_request: Optional[LoRARequest] = None,
) -> None:
self.index = index
self.text = text
self.token_ids = token_ids
self.finish_reason = finish_reason
...
RequestOutput则表示 request 所有序列的输出结果,有它的初始化函数可以看到它记录了对应的 request_id。
class RequestOutput:
def __init__(
self,
request_id: str,
prompt: str,
prompt_token_ids: List[int],
prompt_logprobs: Optional[PromptLogprobs],
outputs: List[CompletionOutput],
finished: bool,
lora_request: Optional[LoRARequest] = None,
) -> None:
self.request_id = request_id
self.prompt = prompt
self.prompt_token_ids = prompt_token_ids
self.outputs = outputs
self.finished = finished
...
我们看看RequestOutput的from_seq_group就能很好理解CompletionOutput和 RequestOutput是如何使用的了。为方便理解,代码有删减,但是不影响最终结果:
class RequestOutput:
@classmethod
def from_seq_group(cls, seq_group: SequenceGroup) -> "RequestOutput":
# 1. Get the top-n sequences.
n = seq_group.sampling_params.n # 每个序列返回的生成序列数量
seqs = seq_group.get_seqs()
# 根据累积 logprob 值来选择出前 n 个生成序列
sorting_key = lambda seq: seq.get_cumulative_logprob()
sorted_seqs = sorted(seqs, key=sorting_key, reverse=True)
top_n_seqs = sorted_seqs[:n]
# 2. Create the outputs.
outputs: List[CompletionOutput] = []
for seq in top_n_seqs:
logprobs = seq.output_logprobs
finshed_reason = SequenceStatus.get_finished_reason(seq.status)
output = CompletionOutput(seqs.index(seq), seq.output_text,
seq.get_output_token_ids(),
seq.get_cumulative_logprob(), logprobs,
finshed_reason)
outputs.append(output)
# Every sequence in the sequence group should have the same prompt.
prompt = seq_group.prompt
prompt_token_ids = seq_group.prompt_token_ids
prompt_logprobs = seq_group.prompt_logprobs
finished = seq_group.is_finished()
return cls(seq_group.request_id,
prompt,
prompt_token_ids,
prompt_logprobs,
outputs,
finished,
lora_request=seq_group.lora_request)
RequestOutput是通过对传入的seq_group: SequenceGroup进行解析后得到的。解析过程主要有两个阶段:
-
- Get the top-n sequences:这一阶段就是对生成序列按照 cumulative_logprob 进行排序,最后选择出top-n 序列。
-
- Create the outputs:将所有top-n生成序列分别转换成
CompletionOutput列表,并作为RequestOutput的初始化参数。
- Create the outputs:将所有top-n生成序列分别转换成